【Tensorflow学习二】神经网络优化方法学习率、激活函数、损失函数、正则化
创始人
2024-03-23 02:36:49
0次
文章目录
- 预备知识
- tf.where
- tf.random.RandomState.rand() 返回一个[0,1)之间的随机数
- np.vstack() 将数组按照垂直方向叠加
- np.mgrid[ ] np.ravel( ) np.c_[ ] 一起使用可以生成网格坐标点
- 复杂度、学习率
- 复杂度
- 指数衰减学习率
- 激活函数
- Sigmoid激活函数
- Tanh激活函数
- ReLu激活函数
- Leaky ReLu激活函数
- 损失函数
- 均方误差
- 交叉熵损失函数
- 自定义损失函数
- Softmax与交叉熵结合
- 欠拟合与过拟合
- 正则化缓解过拟合
预备知识
tf.where
#条件语句真返回A,条件语句假返回B
#tf.where(条件语句,真返回A,假返回B)import tensorflow as tfa=tf.constant([1,2,3,1,1])
b=tf.constant([0,1,3,4,5])
c=tf.where(tf.greater(a,b),a,b)#若a>b,返回a对应位置的元素,否则返回b对应位置的元素
print("c:",c)>>>
c: tf.Tensor([1 2 3 4 5], shape=(5,), dtype=int32)
tf.random.RandomState.rand() 返回一个[0,1)之间的随机数
#返回一个[0,1)之间的随机数
#np.random.RandomState.rand(维度)#维度为空,返回标量
import numpy as np
rdm=np.random.RandomState(seed=1)#seed=常数,每次生成的随机数相同
a=rdm.rand()#返回一个随机标量
b=rdm.rand(2,3)#返回维度为2行3列的随机矩阵print("a:",a)
print("b:",b)
>>>
a: 0.417022004702574
b: [[7.20324493e-01 1.14374817e-04 3.02332573e-01][1.46755891e-01 9.23385948e-02 1.86260211e-01]]
np.vstack() 将数组按照垂直方向叠加
import numpy as np
a=np.array([1,2,3])
b=np.array([4,5,6])
c=np.vstack((a,b))print("c:\n",c)
>>>
c:[[1 2 3][4 5 6]]
np.mgrid[ ] np.ravel( ) np.c_[ ] 一起使用可以生成网格坐标点
#np.mgrid[] np.ravel() np.c_[]一起使用可以生成网格坐标点
# np.mgrid[起始值:结束值:步长,起始值:步长,......]
# x.ravel()将x变为一维数组,“把.向量拉直”
# np.c_[数组1,数组2,...]
import numpy as npx,y=np.mgrid[1:3:1,2:4:0.5]
grid=np.c_[x.ravel(),y.ravel()]
print("x:",x)
print("y:",y)
print("x.ravel():\n", x.ravel())
print("y.ravel():\n", y.ravel())
print("grid:\n",grid)>>>
x: [[1. 1. 1. 1.][2. 2. 2. 2.]]
y: [[2. 2.5 3. 3.5][2. 2.5 3. 3.5]]
x.ravel():[1. 1. 1. 1. 2. 2. 2. 2.]
y.ravel():[2. 2.5 3. 3.5 2. 2.5 3. 3.5]
grid:[[1. 2. ][1. 2.5][1. 3. ][1. 3.5][2. 2. ][2. 2.5][2. 3. ][2. 3.5]]
复杂度、学习率
复杂度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1yMGPdwh-1670312759174)(C:\Users\98306\AppData\Roaming\Typora\typora-user-images\image-20221204210242419.png)]](/webdata/wwwroot/pics.8red.cn/weishitang/202403/8579178ec6cb551.png)
指数衰减学习率
可以先用较大的学习率,快速得到最优解,然后逐步减小学习率,使得模型在训练后期稳定
指数衰减学习率=初试学习率∗学习率衰减率当前轮数/多少轮衰减一次指数衰减学习率=初试学习率*学习率衰减率^{当前轮数/多少轮衰减一次} 指数衰减学习率=初试学习率∗学习率衰减率当前轮数/多少轮衰减一次
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T6BsV8Yk-1670312759176)(C:\Users\98306\AppData\Roaming\Typora\typora-user-images\image-20221204213250545.png)]](/webdata/wwwroot/pics.8red.cn/weishitang/202403/6944c5614dcdc40.png)
激活函数
Sigmoid激活函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G30KRZP3-1670312759176)(C:\Users\98306\AppData\Roaming\Typora\typora-user-images\image-20221204213531093.png)]](/webdata/wwwroot/pics.8red.cn/weishitang/202403/c707751f77caf2.png)
特点:
(1)容易造成梯度消失
(2)输出非0均值,收敛慢(我们希望输入每层神经网络的特征是以0为均值的小数值)
(3)幂运算复杂,训练时间长
Tanh激活函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-78o59Ng1-1670312759177)(C:\Users\98306\AppData\Roaming\Typora\typora-user-images\image-20221204215210928.png)]](/webdata/wwwroot/pics.8red.cn/weishitang/202403/2533c38b1126a1b.png)
特点:
(1)输出是0均值(由于sigmoid的地方)
(2)易造成梯度消失
(3)幂运算复杂,训练时间长
ReLu激活函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ULgKb6c2-1670312759177)(C:\Users\98306\AppData\Roaming\Typora\typora-user-images\image-20221204220112455.png)]](/webdata/wwwroot/pics.8red.cn/weishitang/202403/6e8bc054afdf2db.png)
优点:
(1)解决了梯度消失问题(在正区间)
(2)只需要判断输入是否大于0,计算速度快
(3)收敛速度远快于Sigmoid和Tanh
缺点:
(1)输出非0均值,收敛慢
(2)Dead ReLu问题:某些神经元可能永远无法被激活,导致相应的参数无法被更新(可以改变随机初始化,避免过多的负数特征送入relu函数;可以设置更小的学习率,减小参数分布的巨大变化,避免训练中产生过多负数特征)
Leaky ReLu激活函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZN01M9Tg-1670312759177)(C:\Users\98306\AppData\Roaming\Typora\typora-user-images\image-20221204221053650.png)]](/webdata/wwwroot/pics.8red.cn/weishitang/202403/36f235913616500.png)
为了解决ReLu负区间为0,引起神经元死亡问题而设计的
Leaky ReLu在负区间引入了一个固定的斜率a,使得Leaky ReLu负区间不恒等于0
理论上来讲,Leaky ReLu有ReLu的所有优点,外加不会有Dead Relu问题,但是在实际操作当中,并没有完全证明Leaky ReLu总是好于ReLu。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vLvXikD2-1670312759178)(C:\Users\98306\AppData\Roaming\Typora\typora-user-images\image-20221204221549300.png)]](/webdata/wwwroot/pics.8red.cn/weishitang/202403/d00f6c5e08728a7.png)
损失函数
标签:y_
预测:y
均方误差
均方误差mse:MSE(y^,y)=∑i=1n(y−y^)2n均方误差mse:MSE(\hat{y},y)=\frac{\sum_{i=1}^{n}(y-\hat{y})^2}{n} 均方误差mse:MSE(y^,y)=n∑i=1n(y−y^)2
loss_mse=tf.reduce_mean(tf.square(y_-y))
交叉熵损失函数
H=−∑ylogy^H=-\sum{}ylog\hat{y} H=−∑ylogy^
tf.losses.categorical_crossentropy(y_-y)import tensorflow as tfloss_ce1 = tf.losses.categorical_crossentropy([1, 0], [0.6, 0.4])
loss_ce2 = tf.losses.categorical_crossentropy([1, 0], [0.8, 0.2])
print("loss_ce1:", loss_ce1)
print("loss_ce2:", loss_ce2)
>>>
loss_ce1: tf.Tensor(0.5108256, shape=(), dtype=float32)
loss_ce2: tf.Tensor(0.22314353, shape=(), dtype=float32)
自定义损失函数
可以用tf.where构建损失函数
Softmax与交叉熵结合
分类问题中,输出先经过Softmax函数,再计算y与y_的交叉熵损失函数
Tensorflow提供一个函数,将两者结合
tf.nn.softmax_cross_entropy_with_logits(y_,y)import tensorflow as tf
import numpy as npy_ = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 0, 0], [0, 1, 0]])
y = np.array([[12, 3, 2], [3, 10, 1], [1, 2, 5], [4, 6.5, 1.2], [3, 6, 1]])
y_pro = tf.nn.softmax(y)
loss_ce1 = tf.losses.categorical_crossentropy(y_,y_pro)
loss_ce2 = tf.nn.softmax_cross_entropy_with_logits(y_, y)print('分步计算的结果:\n', loss_ce1)
print('结合计算的结果:\n', loss_ce2)
>>>
分步计算的结果:tf.Tensor(
[1.68795487e-04 1.03475622e-03 6.58839038e-02 2.58349207e+005.49852354e-02], shape=(5,), dtype=float64)
结合计算的结果:tf.Tensor(
[1.68795487e-04 1.03475622e-03 6.58839038e-02 2.58349207e+005.49852354e-02], shape=(5,), dtype=float64)
欠拟合与过拟合
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vonGk6xd-1670312759178)(C:\Users\98306\AppData\Roaming\Typora\typora-user-images\image-20221205103952286.png)]](/webdata/wwwroot/pics.8red.cn/weishitang/202403/a46aee535c4b33d.png)
欠拟合的解决方法:
增加输入特征项
增加网络参数
减少正则化参数
过拟合的解决方法:
数据清洗
增大训练集
采用正则化
增大正则化参数
正则化缓解过拟合
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3lJzzHQS-1670312759179)(C:\Users\98306\AppData\Roaming\Typora\typora-user-images\image-20221205105333057.png)]](/webdata/wwwroot/pics.8red.cn/weishitang/202403/c59cf667126962d.png)
tf.nn.l2_loss(w)
过拟合情况:
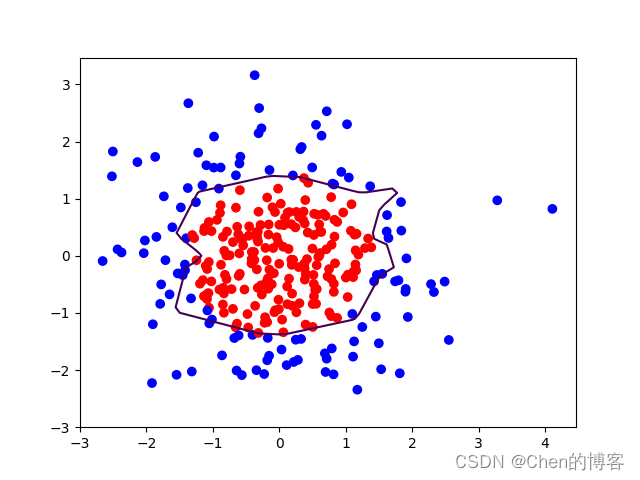
正则化之后:
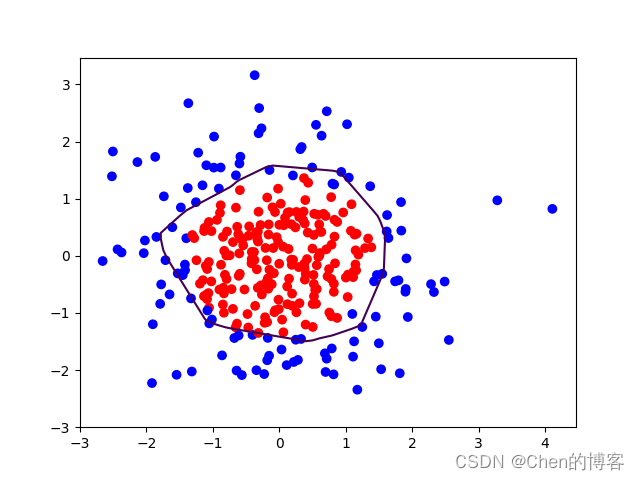
曲线变得更为平缓,有效缓解了过拟合
下面为L2正则化的例子:
with tf.GradientTape() as tape: # 记录梯度信息h1 = tf.matmul(x_train, w1) + b1 # 记录神经网络乘加运算h1 = tf.nn.relu(h1)y = tf.matmul(h1, w2) + b2# 采用均方误差损失函数mse = mean(sum(y-out)^2)loss_mse = tf.reduce_mean(tf.square(y_train - y))# 添加l2正则化loss_regularization = []# tf.nn.l2_loss(w)=sum(w ** 2) / 2loss_regularization.append(tf.nn.l2_loss(w1))loss_regularization.append(tf.nn.l2_loss(w2))# 求和# 例:x=tf.constant(([1,1,1],[1,1,1]))# tf.reduce_sum(x)# >>>6loss_regularization = tf.reduce_sum(loss_regularization)loss = loss_mse + 0.03 * loss_regularization # REGULARIZER = 0.03# 计算loss对各个参数的梯度
variables = [w1, b1, w2, b2]
grads = tape.gradient(loss, variables)# 实现梯度更新
# w1 = w1 - lr * w1_grad
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
相关内容
热门资讯
汽车油箱结构是什么(汽车油箱结...
本篇文章极速百科给大家谈谈汽车油箱结构是什么,以及汽车油箱结构原理图解对应的知识点,希望对各位有所帮...
美国2年期国债收益率上涨15个...
原标题:美国2年期国债收益率上涨15个基点 美国2年期国债收益率上涨15个基...
嵌入式 ADC使用手册完整版 ...
嵌入式 ADC使用手册完整版 (188977万字)💜&#...
重大消息战皇大厅开挂是真的吗...
您好:战皇大厅这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游戏...
盘点十款牵手跑胡子为什么一直...
您好:牵手跑胡子这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游...
senator香烟多少一盒(s...
今天给各位分享senator香烟多少一盒的知识,其中也会对sevebstars香烟进行解释,如果能碰...
终于懂了新荣耀斗牛真的有挂吗...
您好:新荣耀斗牛这款游戏可以开挂,确实是有挂的,需要了解加客服微信8435338】很多玩家在这款游戏...
盘点十款明星麻将到底有没有挂...
您好:明星麻将这款游戏可以开挂,确实是有挂的,需要了解加客服微信【5848499】很多玩家在这款游戏...
总结文章“新道游棋牌有透视挂吗...
您好:新道游棋牌这款游戏可以开挂,确实是有挂的,需要了解加客服微信【7682267】很多玩家在这款游...
终于懂了手机麻将到底有没有挂...
您好:手机麻将这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游戏...