GPT-Chinese 复现
创始人
2024-03-22 16:28:19
0次
github
环境准备
conda -create gpt_cn python=3.7
conda activate gpt_cn
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 -c pytorch
pip install -r requirements.txt
错误
module 'distutils' has no attribute 'version'
- 解决方案:
pip uninstall setuptools
pip install setuptools==59.5.0
构建数据集
测试 build_files 函数
- 这一步的目的是为了看看数据被处理之后长什么样子。方便我们更加自由地构造能够符合训练的数据集
train.py文件中,先测试一下build_files的功能,看看构造出来用于训练的数据集是什么样子的-
- 从 huggingface 上下载一个 bert 预训练模型 然后按照我给出的代码中的方式加载这个
bert预训练模型文件夹中的vocab.txt文件,(如何从 huggingface 中下载 bert 的预训练模型可以参考 这篇文章)
- 从 huggingface 上下载一个 bert 预训练模型 然后按照我给出的代码中的方式加载这个
-
- 在文件目录下创建一个
data文件夹,并自己写一个简单的train.json文件放到里面作为测试
- 在文件目录下创建一个
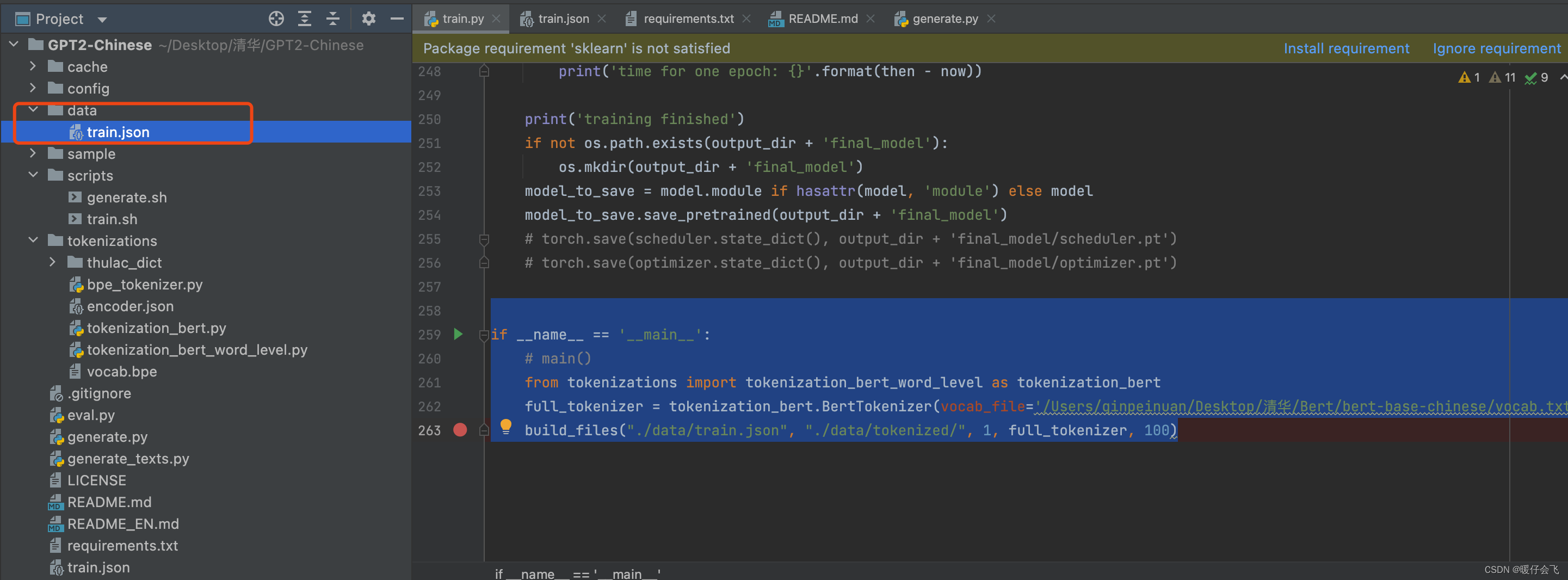
- 这个 train.json 中的内容作者给出了一个示例:就按照这种方式自己造点数据放进去就行
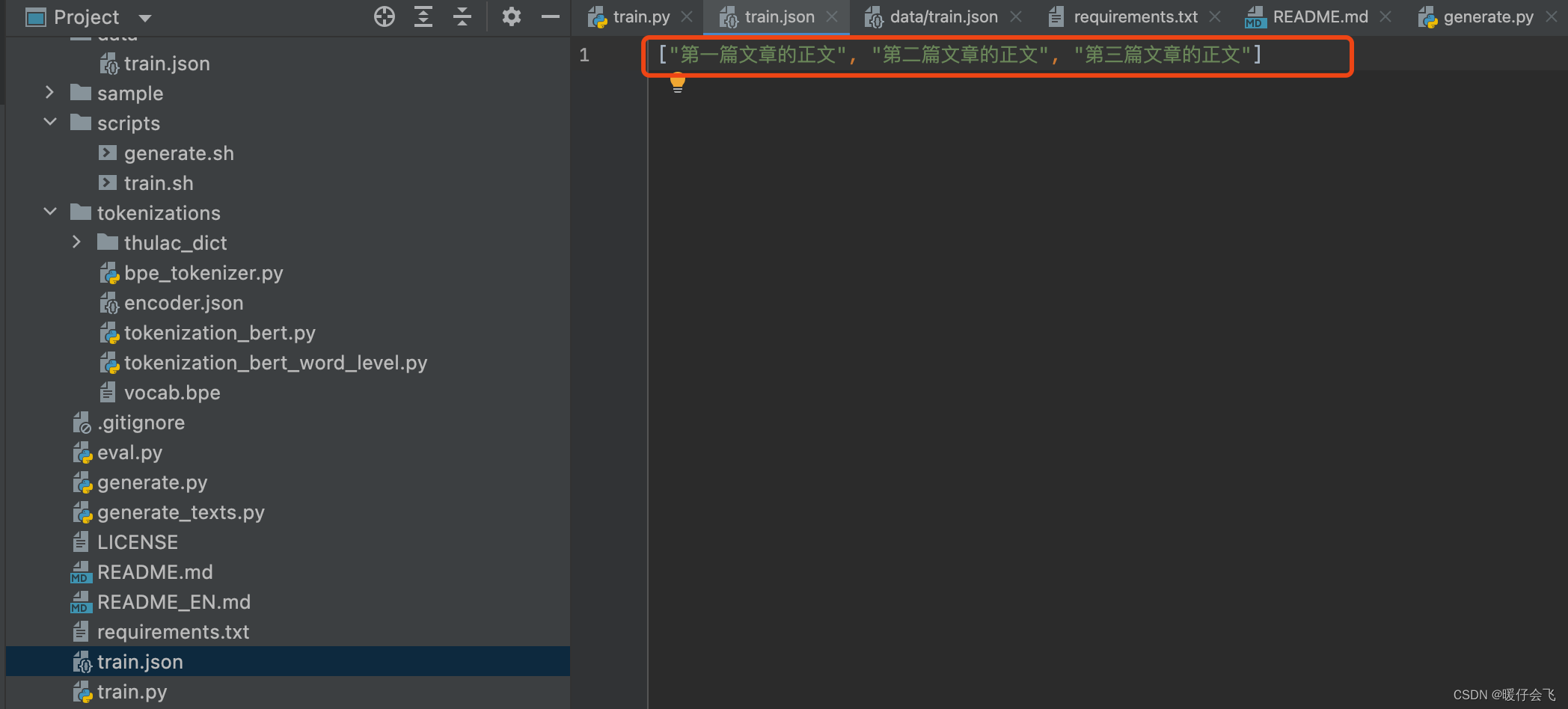
-
def build_files(data_path, tokenized_data_path, num_pieces, full_tokenizer, min_length):""":param data_path: 原始训练语料,json 格式的数据:param tokenized_data_path: tokenized语料存放位置:param num_pieces: 将训练语料分成多少份:param full_tokenizer: 使用的分词器,用 bpe 构造的或者使用 bert-base-chinese 模型的分词器:param min_length: 最短收录文章长度:return:"""with open(data_path, 'r', encoding='utf8') as f:print('reading lines')lines = json.load(f)lines = [line.replace('\n', ' [SEP] ') for line in lines] # 用[SEP]表示换行, 段落之间使用SEP表示段落结束all_len = len(lines)if not os.path.exists(tokenized_data_path):os.mkdir(tokenized_data_path)for i in tqdm(range(num_pieces)):sublines = lines[all_len // num_pieces * i: all_len // num_pieces * (i + 1)]if i == num_pieces - 1:sublines.extend(lines[all_len // num_pieces * (i + 1):]) # 把尾部例子添加到最后一个piecesublines = [full_tokenizer.tokenize(line) for line in sublines iflen(line) > min_length] # 只考虑长度超过min_length的句子sublines = [full_tokenizer.convert_tokens_to_ids(line) for line in sublines]full_line = []for subline in sublines:full_line.append(full_tokenizer.convert_tokens_to_ids('[MASK]')) # 文章开头添加MASK表示文章开始full_line.extend(subline)full_line.append(full_tokenizer.convert_tokens_to_ids('[CLS]')) # 文章之间添加CLS表示文章结束with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'w') as f:for id in full_line:f.write(str(id) + ' ')print('finish')
if __name__ == '__main__':# main()from tokenizations import tokenization_bert_word_level as tokenization_bertfull_tokenizer = tokenization_bert.BertTokenizer(vocab_file='/Users/qinpeinuan/Desktop/清华/Bert/bert-base-chinese/vocab.txt')build_files("./data/train.json", "./data/tokenized/", 1, full_tokenizer, 100)
- 运行这一步成功后,data 中会产生一个
data / tokenized文件夹,其中放着经过 tokenize 处理之后的数据:

- 本文中,作者明确说,这个工作的所有分词都是借助 bert 的 vocab.txt 来完成的。所以大家不要一看这是 GPT 模型就觉得和 BERT 有什么关系?其实他用的就是 bert 的 tokenizer 来分词的。
加载 GPT 预训练模型
- 和上一步的 bert 文件一样,还是从 huggingface 上找一个 GPT 的预训练模型。我下载的是 这个 gpt2-base-chinese
- 然后把这个预训练的 gpt 模型放到自己构建的文件夹下面,我是这么放的:
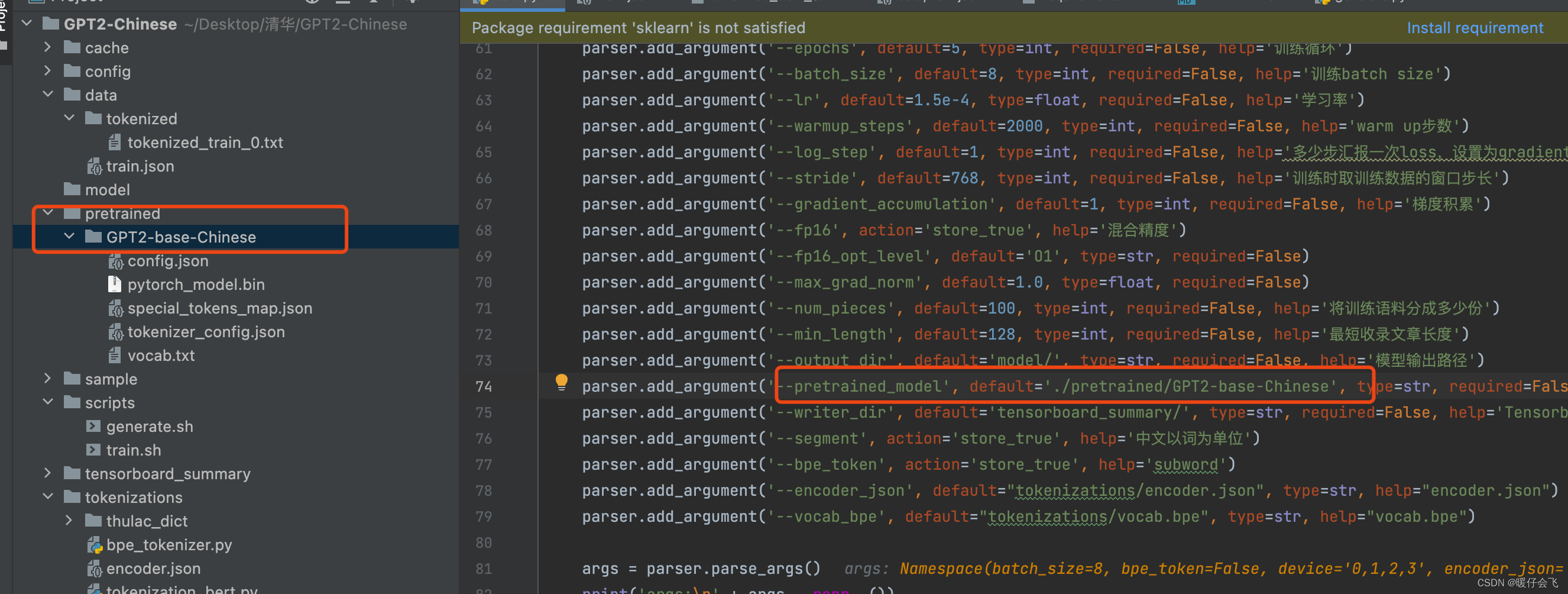
train.py 运行即可
相关内容
热门资讯
汽车油箱结构是什么(汽车油箱结...
本篇文章极速百科给大家谈谈汽车油箱结构是什么,以及汽车油箱结构原理图解对应的知识点,希望对各位有所帮...
美国2年期国债收益率上涨15个...
原标题:美国2年期国债收益率上涨15个基点 美国2年期国债收益率上涨15个基...
嵌入式 ADC使用手册完整版 ...
嵌入式 ADC使用手册完整版 (188977万字)💜&#...
重大消息战皇大厅开挂是真的吗...
您好:战皇大厅这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游戏...
盘点十款牵手跑胡子为什么一直...
您好:牵手跑胡子这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游...
senator香烟多少一盒(s...
今天给各位分享senator香烟多少一盒的知识,其中也会对sevebstars香烟进行解释,如果能碰...
终于懂了新荣耀斗牛真的有挂吗...
您好:新荣耀斗牛这款游戏可以开挂,确实是有挂的,需要了解加客服微信8435338】很多玩家在这款游戏...
盘点十款明星麻将到底有没有挂...
您好:明星麻将这款游戏可以开挂,确实是有挂的,需要了解加客服微信【5848499】很多玩家在这款游戏...
总结文章“新道游棋牌有透视挂吗...
您好:新道游棋牌这款游戏可以开挂,确实是有挂的,需要了解加客服微信【7682267】很多玩家在这款游...
终于懂了手机麻将到底有没有挂...
您好:手机麻将这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游戏...