扩散模型(Diffusion Model)原理与代码解析(一)
一、模型概览
扩散模型的灵感来自于非平衡热力学。定义了一个扩散步骤的马尔可夫链(当前状态只与上一时刻的状态有关),慢慢地向真实数据中添加随机噪声(前向过程),然后学习反向扩散过程(逆扩散过程),从噪声中构建所需的数据样本。
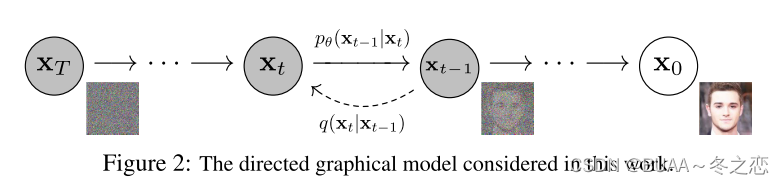
扩散模型有两个过程,分别为扩散过程和逆扩散过程。
如上图所示,扩散过程为从右到左(X0→XT)(X_0 \rightarrow X_T)(X0→XT)的过程,表示对图片逐渐加噪,且Xt+1X_{t+1}Xt+1是在XtX_{t}Xt上加噪得到的,其只受XtX_{t}Xt的影响,因此扩散过程是一个马尔科夫过程。X0X_0X0表示从真实数据集中采样得到的一张图片,对X0X_0X0添加TTT次噪声,图片逐渐变得模糊,当TTT足够大时,XTX_TXT为标准正态分布。在训练过程中,每次添加的噪声是已知的,即q(Xt∣Xt−1)q(X_t|X_{t-1})q(Xt∣Xt−1)是已知的,根据马尔科夫过程的性质,我们可以递归得到q(Xt∣X0)q(X_t|X_0)q(Xt∣X0),即q(Xt∣X0)q(X_t|X_0)q(Xt∣X0)是已知的。扩散过程最主要的就是q(Xt∣X0)q(X_t|X_0)q(Xt∣X0)和q(Xt∣Xt−1)q(X_t|X_{t-1})q(Xt∣Xt−1)的推导,推导细节见下文的扩散过程。
如上图所示,逆扩散过程为从左到右(XT→X0)(X_T \rightarrow X_0)(XT→X0)的过程,表示从噪声中逐渐复原出图片。如果我们能够在给定XtX_tXt条件下知道Xt−1X_{t-1}Xt−1的分布,即如果我们可以知道q(Xt−1∣Xt)q(X_{t-1}|X_t)q(Xt−1∣Xt),那我们就能够从任意一张噪声图片中经过一次次的采样得到一张图片而达成图片生成的目的。显然我们很难知道q(Xt−1∣Xt)q(X_{t-1}|X_t)q(Xt−1∣Xt),因此我们才会用pΘ(Xt−1∣Xt)p_{Θ}(X_{t-1}|X_t)pΘ(Xt−1∣Xt)来近似q(Xt−1∣Xt)q(X_{t-1}|X_t)q(Xt−1∣Xt),pΘ(Xt−1∣Xt)p_{Θ}(X_{t-1}|X_t)pΘ(Xt−1∣Xt)就是我们要训练的网络,在原文中就是个U-Net。而很妙的是,虽然我们不知道q(Xt−1∣Xt)q(X_{t-1}|X_t)q(Xt−1∣Xt),但是q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)却是可以用q(Xt∣X0)q(X_t|X_0)q(Xt∣X0)和q(Xt∣Xt−1)q(X_t|X_{t-1})q(Xt∣Xt−1)表示的,即q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)是可知的,因此我们可以用q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)来指导pΘ(Xt−1∣Xt)p_{Θ}(X_{t-1}|X_t)pΘ(Xt−1∣Xt)进行训练。逆扩散过程最主要的就是q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)的推导,推导细节见下文的逆扩散过程。
二、扩散过程
如上图所示,扩散过程为从右到左(X0→XT)(X_0 \rightarrow X_T)(X0→XT)的过程,表示对图片逐渐加噪,它是不含可学习参数的,且Xt+1X_{t+1}Xt+1是在XtX_{t}Xt上加噪得到的,其只受XtX_{t}Xt的影响,因此扩散过程是一个马尔科夫过程。且每一步扩散的步长受变量{βt∈(0,1)}t=1T\{β_{t} \in (0,1)\}_{t=1}^{T}{βt∈(0,1)}t=1T的影响,且β1<β2<⋯<βT\beta_1<\beta_2<\cdots<\beta_Tβ1<β2<⋯<βT,这意味着所加的噪声是越来越大的。q(Xt∣Xt−1)q(X_{t}|X_{t-1})q(Xt∣Xt−1)可写为如下形式,即给定Xt−1X_{t-1}Xt−1的条件下,XtX_{t}Xt服从均值为1−βtXt−1\sqrt{1-β_{t}}X_{t-1}1−βtXt−1 ,方差为βtIβ_{t}IβtI的正态分布:q(Xt∣Xt−1)=N(Xt;1−βtXt−1,βtI)q(X_{t}|X_{t-1})=N(X_t;\sqrt{1-β_{t}}X_{t-1},β_{t}I)q(Xt∣Xt−1)=N(Xt;1−βtXt−1,βtI)用重参数化技巧表示XtX_tXt,令αt=1−βt\alpha_t=1-\beta_tαt=1−βt,Zt∼N(0,1),t≥0Z_t\sim N(0,1),t\geq0Zt∼N(0,1),t≥0,即:Xt=αtXt−1+1−αtZt−1X_t=\sqrt{\alpha_t}X_{t-1}+\sqrt{1-\alpha_t}Z_{t-1}Xt=αtXt−1+1−αtZt−1为了计算q(Xt∣X0)q(X_t|X_0)q(Xt∣X0),首先由于定义为马尔可夫链,所以给定x0x_0x0条件下x1:Tx_{1:T}x1:T的联合概率分布为q(X1:T∣X0)=∏t=1Tq(Xt∣Xt−1)q(X_{1:T}|X_0)=\prod_{t=1}^Tq(X_{t}|X_{t-1})q(X1:T∣X0)=t=1∏Tq(Xt∣Xt−1)上述式子计算q(Xt∣X0)q(X_t|X_0)q(Xt∣X0)需要不断迭代,我们希望给定X0,βtX_0,\beta_tX0,βt就可以计算出来。给定αt=1−βt,αˉt=∏t=1Tαt\alpha_t=1-\beta_t,\bar{\alpha}_t=\prod_{t=1}^T\alpha_tαt=1−βt,αˉt=∏t=1Tαt,则有:Xt=αtXt−1+1−αtZt−1=αt(αt−1Xt−2+1−αt−1Zt−2)+1−αtZt−1=αtαt−1Xt−2+αt−αtαt−1Zt−2+1−αtZt−1(由于两个正态分布X∼N(μ1,σ1),Y∼N(μ2,σ2)叠加后的分布aX+bY的均值是aμ1+bμ2,方差是a2σ12+b2σ22,所以αt−αtαt−1Zt−2+1−αtZt−1的均值为0,方差为1−αtαt−1,再利用重参数化)=αtαt−1Xt−2+1−αtαt−1Zˉt−2(这里Zˉt−2不同于Zt−2)=⋯=αˉtX0+1−αˉtZˉ\begin{aligned}X_t&=\sqrt{\alpha_t}X_{t-1}+\sqrt{1-\alpha_t}Z_{t-1}\\&=\sqrt{\alpha_t}(\sqrt{\alpha_{t-1}}X_{t-2}+\sqrt{1-\alpha_{t-1}}Z_{t-2})+\sqrt{1-\alpha_t}Z_{t-1}\\&=\sqrt{\alpha_t\alpha_{t-1}}X_{t-2}+\sqrt{\alpha_t-\alpha_t\alpha_{t-1}}Z_{t-2}+\sqrt{1-\alpha_t}Z_{t-1}(由于两个正态分布X\sim N(\mu_1,\sigma_1),Y\sim N(\mu_2,\sigma_2)叠加后的分布aX+bY的均值是a\mu_1+b\mu_2,方差是a^2\sigma_1^2+b^2\sigma_2^2,所以\sqrt{\alpha_t-\alpha_t\alpha_{t-1}}Z_{t-2}+\sqrt{1-\alpha_t}Z_{t-1}的均值为0,方差为1-\alpha_t\alpha_{t-1},再利用重参数化)\\&=\sqrt{\alpha_t\alpha_{t-1}}X_{t-2}+\sqrt{1-\alpha_t\alpha_{t-1}}\bar{Z}_{t-2}(这里\bar{Z}_{t-2}不同于Z_{t-2})\\&=\cdots\\&=\sqrt{\bar{\alpha}_t}X_0+\sqrt{1-\bar{\alpha}_t}\bar{Z}\end{aligned}Xt=αtXt−1+1−αtZt−1=αt(αt−1Xt−2+1−αt−1Zt−2)+1−αtZt−1=αtαt−1Xt−2+αt−αtαt−1Zt−2+1−αtZt−1(由于两个正态分布X∼N(μ1,σ1),Y∼N(μ2,σ2)叠加后的分布aX+bY的均值是aμ1+bμ2,方差是a2σ12+b2σ22,所以αt−αtαt−1Zt−2+1−αtZt−1的均值为0,方差为1−αtαt−1,再利用重参数化)=αtαt−1Xt−2+1−αtαt−1Zˉt−2(这里Zˉt−2不同于Zt−2)=⋯=αˉtX0+1−αˉtZˉ所以,Xt=αˉtX0+1−αˉtZˉ,Zˉ∼N(0,I)X_t=\sqrt{\bar{\alpha}_t}X_0+\sqrt{1-\bar{\alpha}_t}\bar{Z},\bar{Z}\sim N(0,I)Xt=αˉtX0+1−αˉtZˉ,Zˉ∼N(0,I)q(Xt∣X0)=N(Xt;αˉtX0,(1−αˉt)I)q(X_t|X_0)=N(X_t;\sqrt{\bar{\alpha}_t}X_0,(1-\bar{\alpha}_t)I)q(Xt∣X0)=N(Xt;αˉtX0,(1−αˉt)I)至此,我们推出了q(Xt∣Xt−1)q({X_t|X_{t-1}})q(Xt∣Xt−1)和q(Xt∣X0)q(X_t|X_0)q(Xt∣X0)。
三、逆扩散过程
如果我们能够在给定XtX_tXt条件下知道Xt−1X_{t-1}Xt−1的分布,即如果我们可以知道q(Xt−1∣Xt)q(X_{t-1}|X_t)q(Xt−1∣Xt),那我们就能够从任意一张噪声图片中经过一次次的采样得到一张图片而达成图片生成的目的。显然我们很难知道q(Xt−1∣Xt)q(X_{t-1}|X_t)q(Xt−1∣Xt),因此我们才会用pΘ(Xt−1∣Xt)p_{Θ}(X_{t-1}|X_t)pΘ(Xt−1∣Xt)来近似q(Xt−1∣Xt)q(X_{t-1}|X_t)q(Xt−1∣Xt),pΘ(Xt−1∣Xt)p_{Θ}(X_{t-1}|X_t)pΘ(Xt−1∣Xt)就是我们要训练的网络。由于扩散过程中我们每次加的噪声很小,所以我们假设pΘ(Xt−1∣Xt)p_{Θ}(X_{t-1}|X_t)pΘ(Xt−1∣Xt)也是一个高斯分布,可以使用神经网络进行拟合,逆过程也是一个马尔科夫链过程。pΘ(Xt−1∣Xt)=N(Xt−1;μθ(Xt,t),Σθ(Xt,t))p_{Θ}(X_{t-1}|X_t)=N(X_{t-1};\mu_{\theta}(X_t,t),\Sigma_{\theta}(X_t,t))pΘ(Xt−1∣Xt)=N(Xt−1;μθ(Xt,t),Σθ(Xt,t))pΘ(X0:T)=p(XT)∏t=1Tpθ(Xt−1∣Xt)p_{Θ}(X_{0:T})=p(X_T)\prod_{t=1}^Tp_{\theta}(X_{t-1}|X_t)pΘ(X0:T)=p(XT)t=1∏Tpθ(Xt−1∣Xt)
而很妙的是,虽然我们不知道q(Xt−1∣Xt)q(X_{t-1}|X_t)q(Xt−1∣Xt),但是q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)却是可以用q(Xt∣X0)q(X_t|X_0)q(Xt∣X0)和q(Xt∣Xt−1)q(X_t|X_{t-1})q(Xt∣Xt−1)表示的,即q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)是可知的。下面对q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)进行推导:q(Xt−1∣XtX0)=q(X0Xt−1Xt)q(X0Xt)=q(X0Xt−1Xt)q(X0Xt−1)q(X0Xt−1)q(X0Xt)=q(Xt∣Xt−1X0)∗q(Xt−1∣X0)q(Xt∣X0)\begin{aligned}q(X_{t-1}|X_tX_0)&=\frac{q(X_0X_{t-1}X_t)}{q(X_0X_t)}\\&=\frac{q(X_0X_{t-1}X_t)}{q(X_0X_{t-1})}\frac{q(X_0X_{t-1})}{q(X_0X_t)}\\&=q(X_t|X_{t-1}X_0)*\frac{q(X_{t-1}|X_0)}{q({X_t|X_0})}\end{aligned}q(Xt−1∣XtX0)=q(X0Xt)q(X0Xt−1Xt)=q(X0Xt−1)q(X0Xt−1Xt)q(X0Xt)q(X0Xt−1)=q(Xt∣Xt−1X0)∗q(Xt∣X0)q(Xt−1∣X0)由于扩散过程是马尔科夫过程,因此q(Xt∣Xt−1X0)=q(Xt∣Xt−1)q(X_t|X_{t-1}X_0)=q(X_t|X_{t-1})q(Xt∣Xt−1X0)=q(Xt∣Xt−1)q(Xt−1∣XtX0)=q(Xt∣Xt−1)∗q(Xt−1∣X0)q(Xt∣X0)q(X_{t-1}|X_tX_0)=q(X_t|X_{t-1})*\frac{q(X_{t-1}|X_0)}{q({X_t|X_0})}q(Xt−1∣XtX0)=q(Xt∣Xt−1)∗q(Xt∣X0)q(Xt−1∣X0)至此,已经把q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)用q(Xt∣X0)q(X_t|X_0)q(Xt∣X0)和q(Xt∣Xt−1)q(X_t|X_{t-1})q(Xt∣Xt−1)进行表示,下面对q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)的表达式进行推导:q(Xt∣Xt−1)=N(Xt;1−βtXt−1,βtI)=12π(1−αt)exp(−12(Xt−αtXt−1)21−αt)q(X_t|X_{t-1})=N(X_t;\sqrt{1-\beta_t}X_{t-1},\beta_tI)=\frac{1}{\sqrt{2\pi(1-\alpha_t)}}exp\left(-\frac{1}{2}\frac{(X_t-\sqrt{\alpha_t}X_{t-1})^2}{1-\alpha_t}\right)q(Xt∣Xt−1)=N(Xt;1−βtXt−1,βtI)=2π(1−αt)1exp(−211−αt(Xt−αtXt−1)2)q(Xt∣X0)=N(Xt;αˉtX0,(1−αˉt)I)=12π(1−αˉt)exp(−12(Xt−αˉtX0)21−αˉt)q(X_t|X_0)=N(X_t;\sqrt{\bar{\alpha}_t}X_0,(1-\bar{\alpha}_t)I)=\frac{1}{\sqrt{2\pi(1-\bar{\alpha}_t)}}exp\left(-\frac{1}{2}\frac{(X_t-\sqrt{\bar{\alpha}_t}X_0)^2}{1-\bar{\alpha}_t}\right)q(Xt∣X0)=N(Xt;αˉtX0,(1−αˉt)I)=2π(1−αˉt)1exp(−211−αˉt(Xt−αˉtX0)2)q(Xt−1∣X0)=N(Xt−1;αˉt−1X0,(1−αˉt−1)I)=12π(1−αˉt−1)exp(−12(Xt−1−αˉt−1X0)21−αˉt−1)q(X_{t-1}|X_0)=N(X_{t-1};\sqrt{\bar{\alpha}_{t-1}}X_0,(1-\bar{\alpha}_{t-1})I)=\frac{1}{\sqrt{2\pi(1-\bar{\alpha}_{t-1})}}exp\left(-\frac{1}{2}\frac{(X_{t-1}-\sqrt{\bar{\alpha}_{t-1}}X_0)^2}{1-\bar{\alpha}_{t-1}}\right)q(Xt−1∣X0)=N(Xt−1;αˉt−1X0,(1−αˉt−1)I)=2π(1−αˉt−1)1exp(−211−αˉt−1(Xt−1−αˉt−1X0)2)
q(Xt−1∣XtX0)=12π1−αˉt−11−αˉtβtexp(−121−αˉt−11−αˉtβtXt−12−2((1−αˉt−1)αtXt1−αˉt+βtαˉt−1X01−αˉt)Xt−1+C(X0,Xt))q(X_{t-1}|X_tX_0)=\frac{1}{\sqrt{2\pi\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\beta_t}}exp\left(-\frac{1}{2\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\beta_t}X_{t-1}^2-2\left(\frac{(1-\bar{\alpha}_{t-1})\sqrt{\alpha_t}X_t}{1-\bar{\alpha}_t}+\frac{\beta_t\sqrt{\bar{\alpha}_{t-1}}X_0}{1-\bar{\alpha}_t}\right)X_{t-1}+C(X_0,X_t)\right)q(Xt−1∣XtX0)=2π1−αˉt1−αˉt−1βt1exp(−21−αˉt1−αˉt−1βt1Xt−12−2(1−αˉt(1−αˉt−1)αtXt+1−αˉtβtαˉt−1X0)Xt−1+C(X0,Xt))q(Xt−1∣XtX0)=N(Xt−1;(1−αˉt−1)αtXt1−αˉt+βtαˉt−1X01−αˉt,1−αˉt−11−αˉtβt)q(X_{t-1}|X_tX_0)=N\left(X_{t-1};\frac{(1-\bar{\alpha}_{t-1})\sqrt{\alpha_t}X_t}{1-\bar{\alpha}_t}+\frac{\beta_t\sqrt{\bar{\alpha}_{t-1}}X_0}{1-\bar{\alpha}_t},\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\beta_t\right)q(Xt−1∣XtX0)=N(Xt−1;1−αˉt(1−αˉt−1)αtXt+1−αˉtβtαˉt−1X0,1−αˉt1−αˉt−1βt)因为Xt=αˉtX0+1−αˉtZ,Z∼N(0,I)X_t=\sqrt{\bar{\alpha}_t}X_0+\sqrt{1-\bar{\alpha}_t}Z,Z\sim N(0,I)Xt=αˉtX0+1−αˉtZ,Z∼N(0,I)所以μˉ(Xt,X0)=(1−αˉt−1)αtXt1−αˉt+βtαˉt−1X01−αˉt=αt(1−αˉt−1)1−αˉtXt+αˉt−1βt1−αˉt(1αˉt(Xt−1−αˉtZ))#(已知Xt的情况下,X0可以用Xt表示)=αt(1−αˉtαt)αt(1−αˉt)Xt+αˉt−1(1−αt)1−αˉt1αtαˉt−1(Xt−1−αˉtZ)=αt−αˉt+1−αtαt(1−αˉt)Xt−1−αtαt1−αˉtZ=1αt(Xt−βt1−αˉtZ)\begin{aligned}\bar{\mu}(X_t,X_0)&=\frac{(1-\bar{\alpha}_{t-1})\sqrt{\alpha_t}X_t}{1-\bar{\alpha}_t}+\frac{\beta_t\sqrt{\bar{\alpha}_{t-1}}X_0}{1-\bar{\alpha}_t}\\&=\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}X_t+\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}\left(\frac{1}{\sqrt{\bar{\alpha}_t}}\left(X_t-\sqrt{1-\bar{\alpha}_t}Z\right)\right)\space\space\#(已知X_t的情况下,X_0可以用X_t表示)\\&=\frac{\alpha_t(1-\frac{\bar{\alpha}_{t}}{\alpha_t})}{\sqrt{\alpha_t}(1-\bar{\alpha}_t)}X_t+\frac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t}\frac{1}{\sqrt{\alpha_t}\sqrt{\bar{\alpha}_{t-1}}}\left(X_t-\sqrt{1-\bar{\alpha}_t}Z\right)\\&=\frac{\alpha_t-\bar{\alpha}_t+1-\alpha_t}{\sqrt{\alpha_t}(1-\bar{\alpha}_t)}X_t-\frac{1-\alpha_t}{\sqrt{\alpha_t}\sqrt{1-\bar{\alpha}_{t}}}Z\\&=\frac{1}{\sqrt{\alpha_t}}\left(X_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}Z\right)\end{aligned}μˉ(Xt,X0)=1−αˉt(1−αˉt−1)αtXt+1−αˉtβtαˉt−1X0=1−αˉtαt(1−αˉt−1)Xt+1−αˉtαˉt−1βt(αˉt1(Xt−1−αˉtZ)) #(已知Xt的情况下,X0可以用Xt表示)=αt(1−αˉt)αt(1−αtαˉt)Xt+1−αˉtαˉt−1(1−αt)αtαˉt−11(Xt−1−αˉtZ)=αt(1−αˉt)αt−αˉt+1−αtXt−αt1−αˉt1−αtZ=αt1(Xt−1−αˉtβtZ)所以q(Xt−1∣XtX0)=N(Xt−1;1αt(Xt−βt1−αˉtZ),1−αˉt−11−αˉtβt),Z∼N(0,I)q(X_{t-1}|X_tX_0)=N\left(X_{t-1};\frac{1}{\sqrt{\alpha_t}}\left(X_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}Z\right),\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\beta_t\right),Z\sim N(0,I)q(Xt−1∣XtX0)=N(Xt−1;αt1(Xt−1−αˉtβtZ),1−αˉt1−αˉt−1βt),Z∼N(0,I)至此,得到了q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)的分布表达式。接下来,我们介绍怎么用q(Xt−1∣XtX0)q(X_{t-1}|X_tX_0)q(Xt−1∣XtX0)来监督pΘ(Xt−1∣Xt)p_{\Theta}(X_{t-1}|X_t)pΘ(Xt−1∣Xt)进行训练。