【Python项目】Python基于tkinter实现一个笔趣阁小说下载器 | 附源码
创始人
2024-03-22 07:28:21
0次
前言
halo,包子们上午好
笔趣阁小说应该很多小伙伴都知道
但是用Python实现一个笔趣阁小说下载器
那不是爽歪歪呀
基于tkinter实现的Python版本的笔趣阁小说下载器今天小编给大家实现了
相关文件
关注小编,私信小编领取哟!
当然别忘了一件三连哟~~
源码点击蓝色字体领取
Python零基础入门到精通视频合集
【整整800集】Python爬虫项目零基础入门合集,细狗都学会了,你还不会?
开发工具
Python版本:3.7.8
相关模块:
tkinter模块;
json模块;
以及一些python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
效果展示
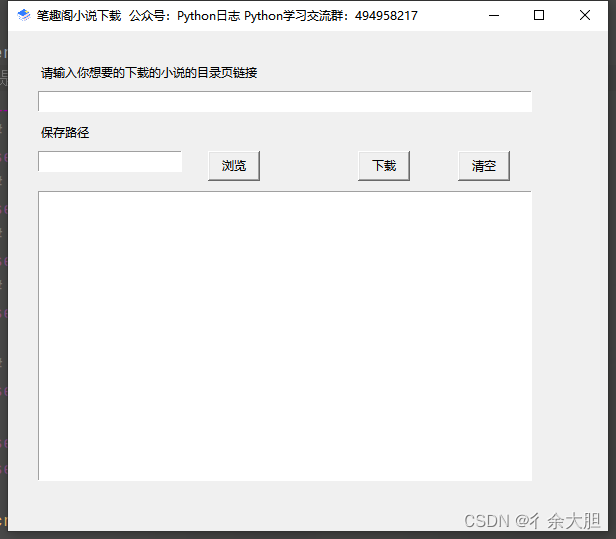
代码展示
模块导入
import tkinter
# 把导入的方法当做普通的方法使用
from download import get_one_book, get_book_links, save_text, download_one_chapter页面布局
class Query:# 类 是一整个页面def __init__(self, master):# 类里面固定的一个方法self.root = master# 设置窗口对象的大小self.root.geometry('600x500+100+100')# 设置窗口的标题self.root.title('笔趣阁小说下载 公众号:Python日志 Python学习交流群:494958217')# 设置窗口的图标self.root.iconbitmap('favicon.ico')# tkinter 的特殊变量,可以与组件里面的文字进行绑定self.index_url = tkinter.StringVar()self.create_page()self.handle_event()def create_page(self):"""创建页面"""# label 文本框tkinter.Label(self.root, text='请输入你想要的下载的小说的目录页链接').place(x=30, y=30)# 输入框 entry 只是布局了一个控件tkinter.Entry(self.root, width=70, textvariable=self.index_url).place(x=30, y=60)# 保存路径tkinter.Label(self.root, text='保存路径').place(x=30, y=90)# # 路径标签tkinter.Entry(self.root).place(x=30, y=120)self.button1 = tkinter.Button(self.root, text='浏览', width=6, height=1)self.button1.place(x=200, y=120)self.button2 = tkinter.Button(self.root, text='下载', width=6, height=1)self.button2.place(x=350, y=120)self.button3 = tkinter.Button(self.root, text='清空', width=6, height=1)self.button3.place(x=450, y=120)# 文本框self.text = tkinter.Text(self.root, width=70, height=22)self.text.place(x=30, y=160)def handle_event(self):# 点击下载,就开始下载小说# 拿到需要的链接,# 当下载按钮被点击的时候,获取下载地址,然后再进行下载self.button2['command'] = self.download_bookdef download_book(self):book_url = self.index_url.get()if book_url:print(book_url)# 下载小说逻辑之前公开课已经实现过了,直接导入使用# 调用方法,获取每一章的下载地址links = get_book_links(book_url)for link in links:print(book_url + link)# 调用现有的逻辑,实现一章小说的下载title, text = download_one_chapter(book_url + link)save_text(title, text)# 把下载的信息插入的 text 文本框里面去# 第0行,第0个self.text.insert(0.0, f'{title} 下载成功\n')self.text.update()else:messagebox.showinfo(title='提示', message='下载链接不能为空')
网址请求
# 模拟浏览器发送请求
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}def download_one_chapter(target_url):# 需要请求的网址# target_url = 'http://www.shuquge.com/txt/8659/2324753.html'# response 服务返回的内容 对象# pycharm ctrl+鼠标左键response = requests.get(target_url, headers=headers)# 解码 万能解码response.encoding = response.apparent_encoding# 文字方法 获取网页文字内容# print(response.text)# 字符串html = response.text"""从网页源代码里面拿到信息"""# 使用parsel 把字符串变成对象sel = parsel.Selector(html)# scrapy# extract 提取标签的内容# 伪类选择器(选择属性) css选择器(选择标签)# 提取第一个内容title = sel.css('.content h1::text').extract_first()# 提取所有的内容contents = sel.css('#content::text').extract()print(title)# print(contents)""" 数据清除 清除空白字符串 """# contents1 = []# for content in contents:# # 去除两端空白字符# # 字符串的操作 列表的操作# contents1.append(content.strip())## print(contents1)# 列表推导式contents1 = [content.strip() for content in contents]# print(contents1)# 把列表编程字符串text = '\n'.join(contents1)# print(text)return title, text
保存小说
def save_text(title, text):"""保存小说内容"""# open 操作文件(写入、读取)file = open(title + '.txt', mode='w', encoding='utf-8')# 只能写入字符串file.write(title)file.write(text)# 关闭文件file.close()传入一本小说的目录
def get_book_links(book_url):response = requests.get(book_url)response.encoding = response.apparent_encodinghtml = response.textsel = parsel.Selector(html)links = sel.css('dd a::attr(href)').extract()return links下载一本小说
def get_one_book(book_url):links = get_book_links(book_url)for link in links[12:]:# print('http://www.shuquge.com/txt/8659/' + link)download_one_chapter(book_url + link)
总结
部门重要代码已经在上方给大家展示出来了,源码领取可以看相关文件或者后台找小编哟
相关内容
热门资讯
汽车油箱结构是什么(汽车油箱结...
本篇文章极速百科给大家谈谈汽车油箱结构是什么,以及汽车油箱结构原理图解对应的知识点,希望对各位有所帮...
美国2年期国债收益率上涨15个...
原标题:美国2年期国债收益率上涨15个基点 美国2年期国债收益率上涨15个基...
嵌入式 ADC使用手册完整版 ...
嵌入式 ADC使用手册完整版 (188977万字)💜&#...
重大消息战皇大厅开挂是真的吗...
您好:战皇大厅这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游戏...
盘点十款牵手跑胡子为什么一直...
您好:牵手跑胡子这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游...
senator香烟多少一盒(s...
今天给各位分享senator香烟多少一盒的知识,其中也会对sevebstars香烟进行解释,如果能碰...
终于懂了新荣耀斗牛真的有挂吗...
您好:新荣耀斗牛这款游戏可以开挂,确实是有挂的,需要了解加客服微信8435338】很多玩家在这款游戏...
盘点十款明星麻将到底有没有挂...
您好:明星麻将这款游戏可以开挂,确实是有挂的,需要了解加客服微信【5848499】很多玩家在这款游戏...
总结文章“新道游棋牌有透视挂吗...
您好:新道游棋牌这款游戏可以开挂,确实是有挂的,需要了解加客服微信【7682267】很多玩家在这款游...
终于懂了手机麻将到底有没有挂...
您好:手机麻将这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游戏...