Windows+Visual stdio+CUDA编程方式及测试
目录
- 一、visual stdio内针对工程的配置
- 1、新建一个空项目
- 2、配置CUDA生成依赖项
- 3、配置基本库目录
- 4、配置静态链接库路径
- 5、配置源码文件风格
- 6、扩展文件名配置
- 二、样例测试
- 测试样例1
- 样例1问题:找不到helper_cuda.h文件
- 测试样例2
- 测试样例3
一、visual stdio内针对工程的配置
1、新建一个空项目
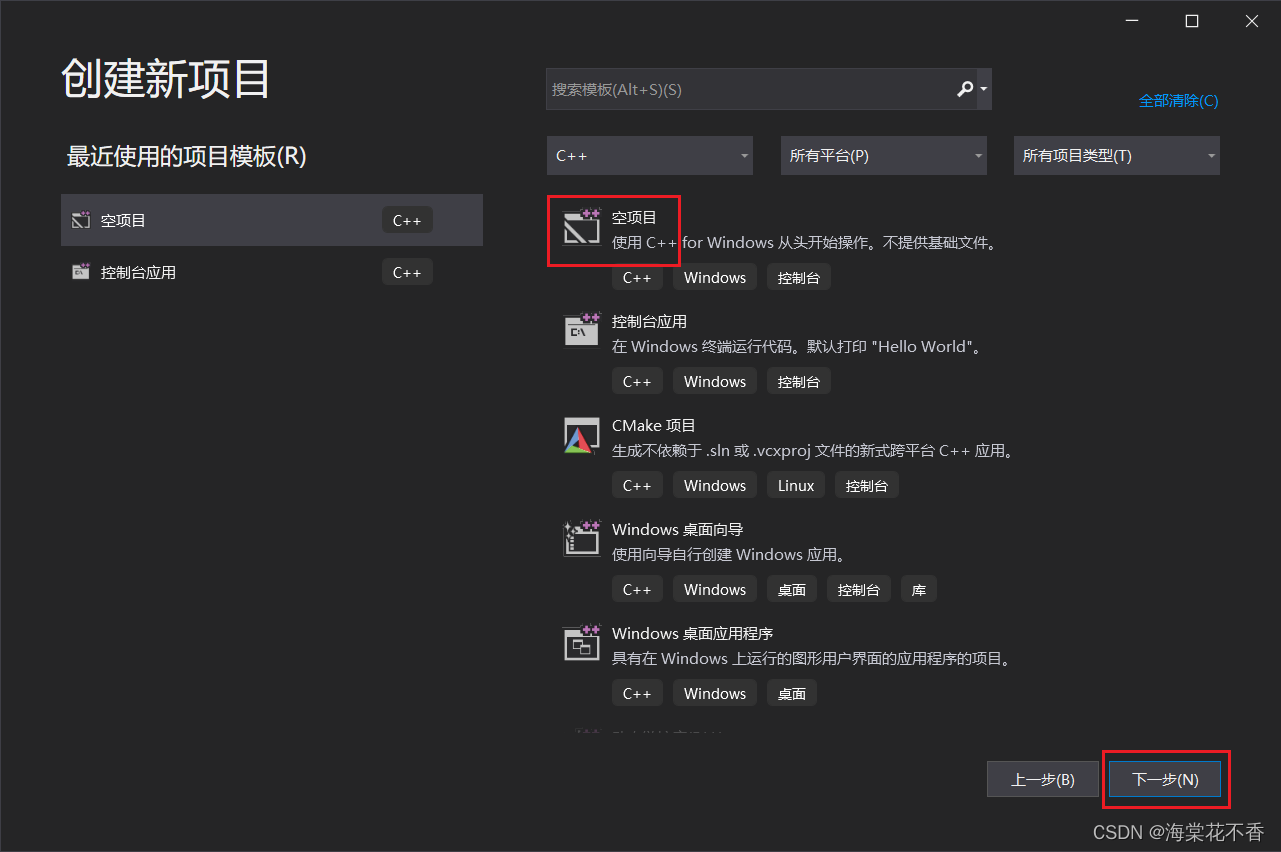
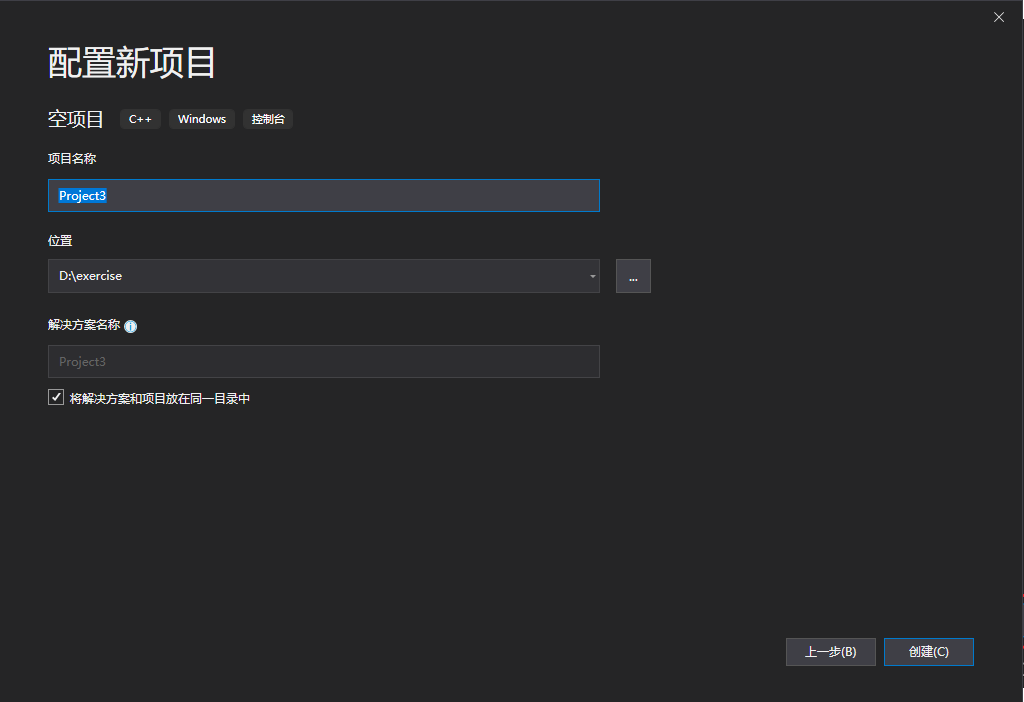
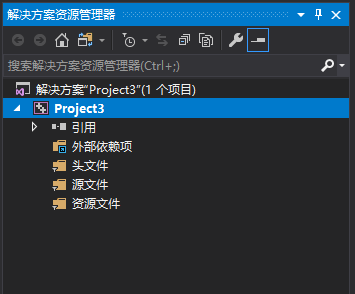
建立好的工程右侧解决方案栏应该包含一下几个文件
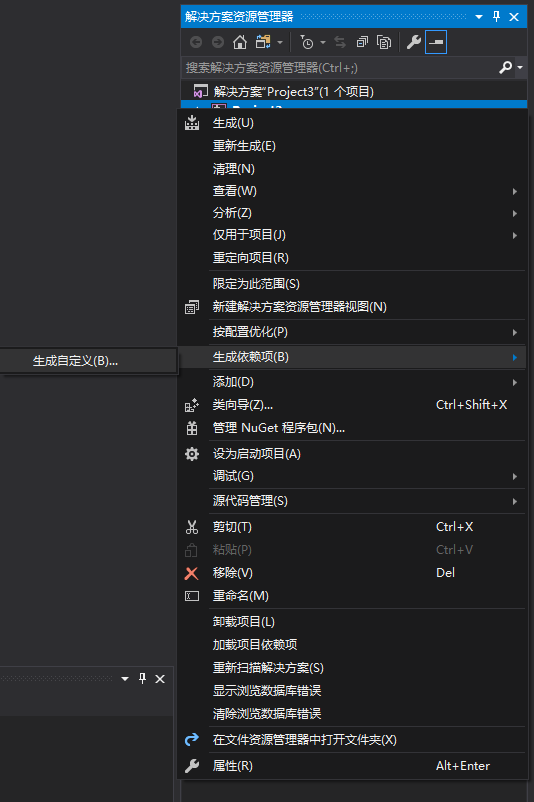
2、配置CUDA生成依赖项
选中工程(建立的工程名,如图中的project3),右键–生成依赖项-生成自定义
在打开的窗口找到CUDA项选中:
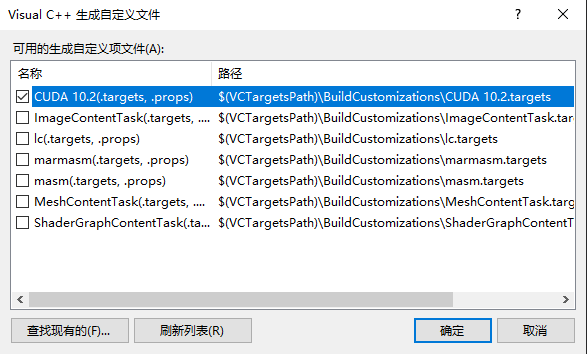
PS-----这里遇到找不到CUDA的问题,解决方案:
如果没有列表中没有,点击 “查找现有的”。 在cuda的安装目录下,默认安装的,一般在: C:\ProgramFiles\NVIDIAGPUComputingToolkit\CUDA\v10.0\extras\visual_studio_integration\MSBuildExtensions
添加里面的文件进来就行, 然后选择,确定。
3、配置基本库目录
右键工程→ 属性→ VC++目录 → 包含目录,添加以下目录(根据自己安装位置确定找到对应文件):
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2\common\inc
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include
ProgramData在C盘中有时是隐藏状态,在编辑栏的查看项中打开隐藏文件选项即可看到
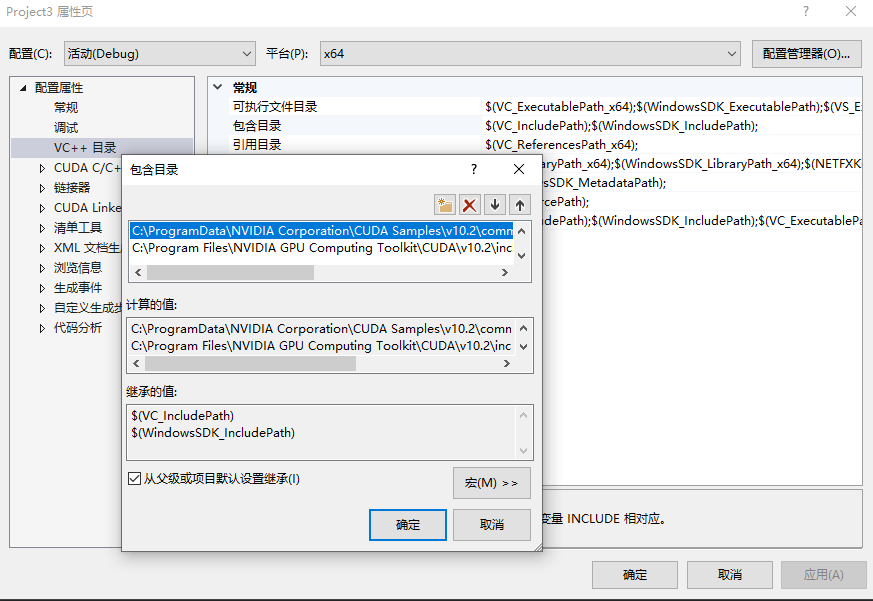
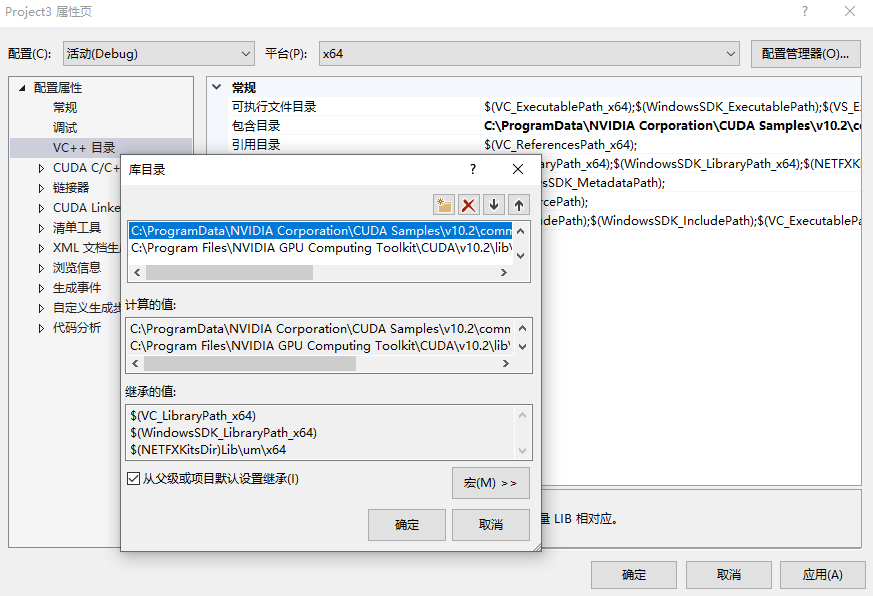
在库目录中添加以下目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2\common\lib\x64
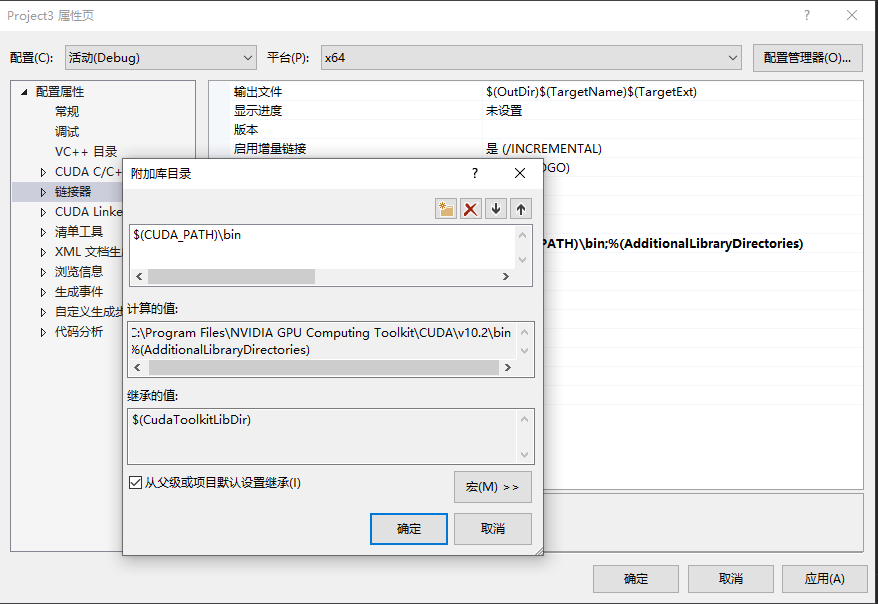
4、配置静态链接库路径
右键项目 → 属性 → 配置属性 → 链接器 → 常规 → 附加库目录,添加以下目录:
点击添加图标,输入$(CUDA_PATH)\bin,确定。(这个指令会自动计算bin文件夹所在位置并添加到目录中,当然也可以直接找到文件目录整体添加进去)
链接器 → 输入 → 附加依赖项
这里面已有一些库名:
kernel32.lib;user32.lib;gdi32.lib;winspool.lib;comdlg32.lib;advapi32.lib;shell32.lib;ole32.lib;oleaut32.lib;uuid.lib;odbc32.lib;odbccp32.lib;%(AdditionalDependencies)
这些库为原有!
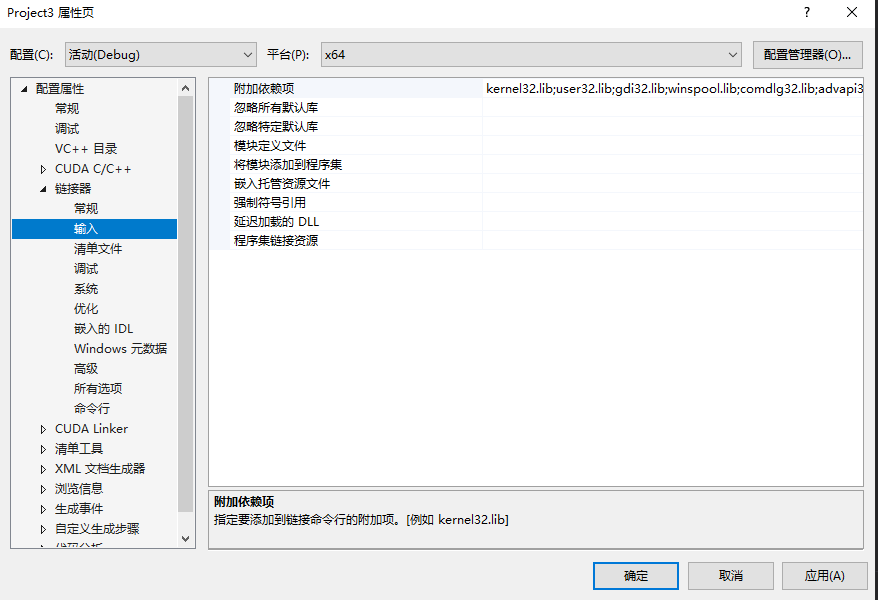
这里可以看到系统已经将一些Lib库文件名加进去了,但是做一些项目的时候发现会报错:找不到***库的情况,此时,就需要手动添加一些,如果仅仅是lib文件在,名字没添加,可以在这里添加,但如果是文件没有就需要下载再添加。下面给出一些大部分系统都有的lib库名:
cublas.lib;cublas_device.lib;cuda.lib;cudadevrt.lib;cudart.lib;cudart_static.lib;cufft.lib;cufftw.lib;curand.lib;cusolver.lib;cusparse.lib;nppc.lib;nppial.lib;nppicc.lib;nppicom.lib;nppidei.lib;nppif.lib;nppig.lib;nppim.lib;nppist.lib;nppisu.lib;nppitc.lib;npps.lib;nvblas.lib;nvcuvid.lib;nvgraph.lib;nvml.lib;nvrtc.lib;OpenCL.lib;
以上也是 “第3步” 中添加的库目录 “C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64” 中的库!
5、配置源码文件风格
配置这个后,建立CUDA工程或者添加CUDA项中写入的代码就会变得有颜色。
右键源文件 → 添加 → 新建项 → CUDA C/C++ File,输入.cu文件名建立一个cu源文件
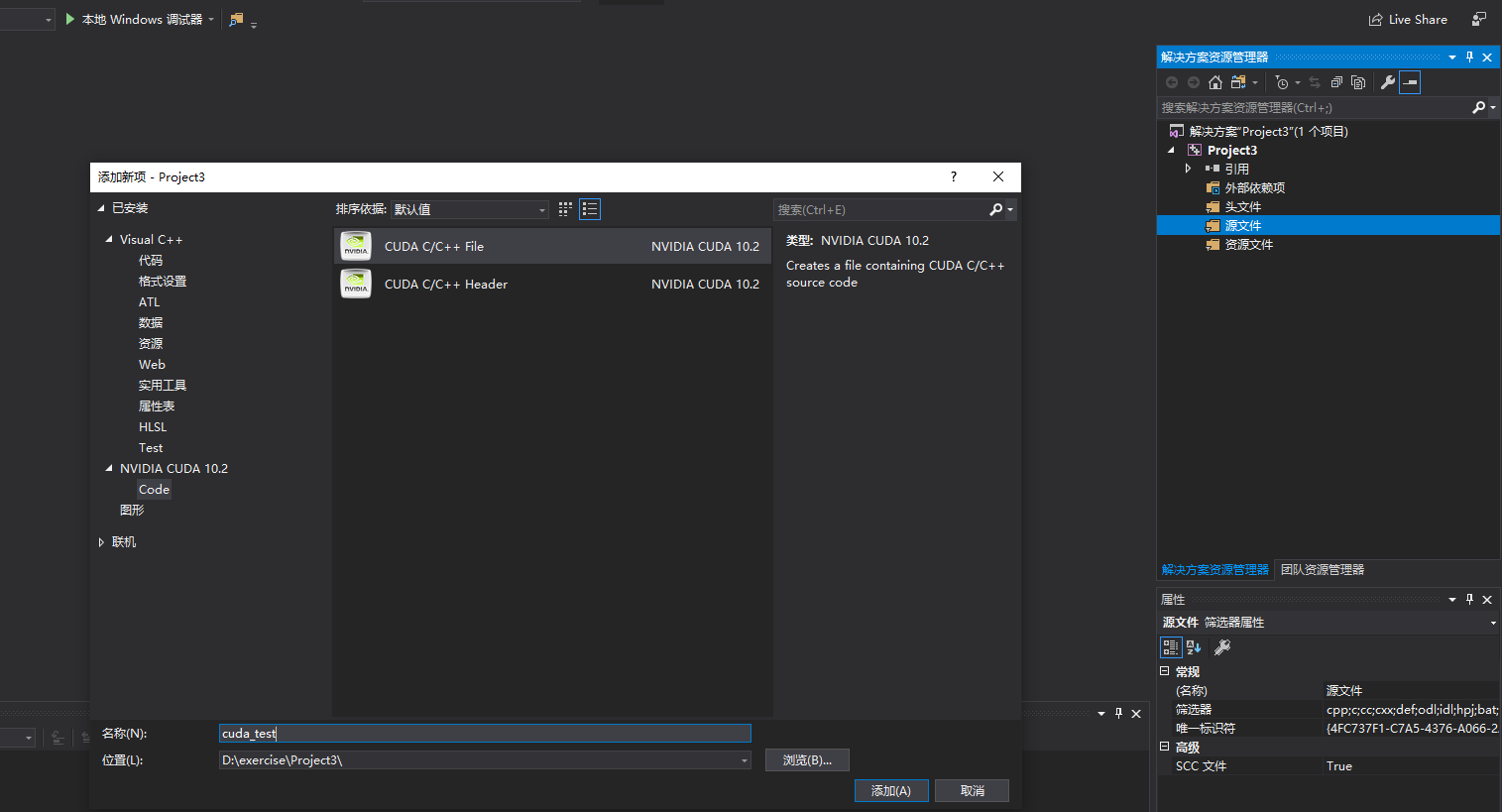
右键 “xxx.cu" 源文件 → 属性 → 配置属性 → 常规 → 项类型 → 设置为“CUDA C/C++”
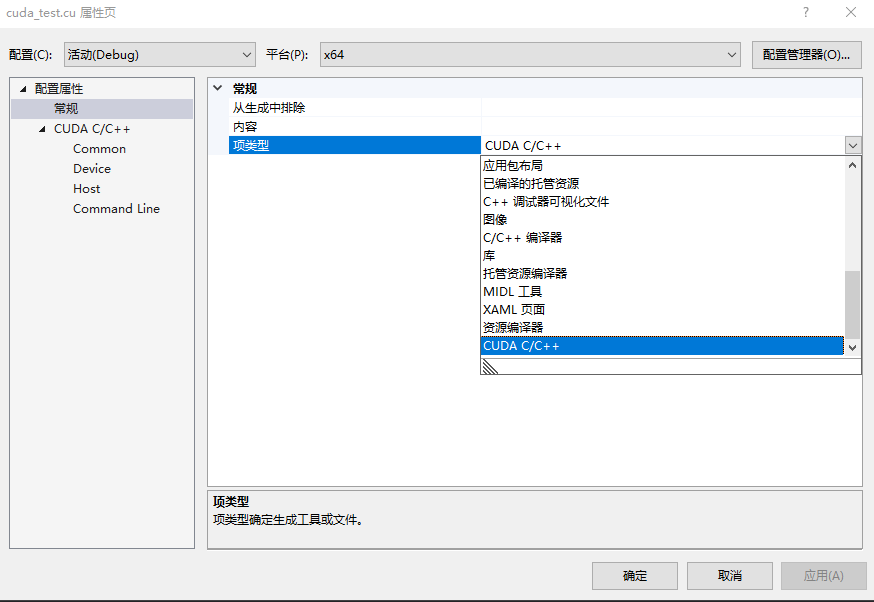
6、扩展文件名配置
针对安装好后没有CUDA模块问题)
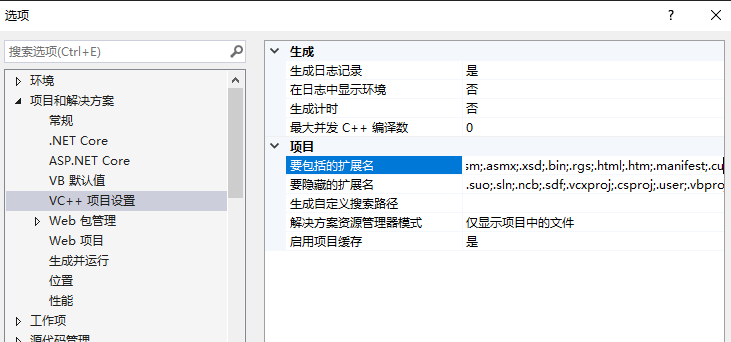
(1)工具->选项->文本编辑器->文件拓展名, 新增扩展名 .cu 、.cuh 编辑器 Microsoft Visual C++ 添加
(2)工具->选项->项目和解决方案->vc++项目设置->要包括的拓展名
将 .cu和.cuh 加上,用分号 ; 隔开
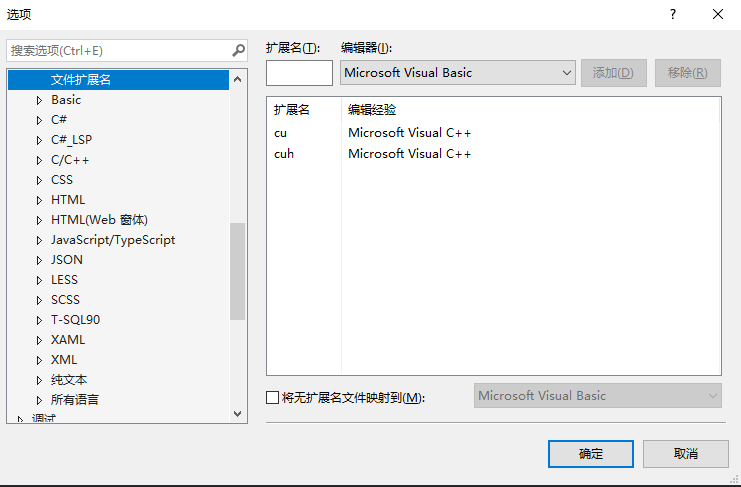
以上步骤参考网页
二、样例测试
有两种方式进行CUDA编程:
(1)创建工程→ 空项目→ 右键源文件 → 添加 → 新建项 → CUDA C/C++ File
可以得到.cu文件进行CUDA开发
(2)创建工程→ 搜索到CUDA runtime→ 创建
这样新建后会看到一个kernel.cu文件,是系统自带的测试样例,把他的内容删除就可以开始自己的开发了
本文选用第二种方式:
测试样例1
这是sample中的一个代码VectorAdd
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);__global__ void addKernel(int *c, const int *a, const int *b)
{int i = threadIdx.x;c[i] = a[i] + b[i];
}int main()
{const int arraySize = 5;const int a[arraySize] = { 1, 2, 3, 4, 5 };const int b[arraySize] = { 10, 20, 30, 40, 50 };int c[arraySize] = { 0 };// Add vectors in parallel.cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);if (cudaStatus != cudaSuccess) {fprintf(stderr, "addWithCuda failed!");return 1;}printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0], c[1], c[2], c[3], c[4]);// cudaDeviceReset must be called before exiting in order for profiling and// tracing tools such as Nsight and Visual Profiler to show complete traces.cudaStatus = cudaDeviceReset();if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaDeviceReset failed!");return 1;}return 0;
}// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{int *dev_a = 0;int *dev_b = 0;int *dev_c = 0;cudaError_t cudaStatus;// Choose which GPU to run on, change this on a multi-GPU system.cudaStatus = cudaSetDevice(0);if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");goto Error;}// Allocate GPU buffers for three vectors (two input, one output) .cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMalloc failed!");goto Error;}cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMalloc failed!");goto Error;}cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMalloc failed!");goto Error;}// Copy input vectors from host memory to GPU buffers.cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMemcpy failed!");goto Error;}cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMemcpy failed!");goto Error;}// Launch a kernel on the GPU with one thread for each element.addKernel << <1, size >> > (dev_c, dev_a, dev_b);// Check for any errors launching the kernelcudaStatus = cudaGetLastError();if (cudaStatus != cudaSuccess) {fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));goto Error;}// cudaDeviceSynchronize waits for the kernel to finish, and returns// any errors encountered during the launch.cudaStatus = cudaDeviceSynchronize();if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);goto Error;}// Copy output vector from GPU buffer to host memory.cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMemcpy failed!");goto Error;}Error:cudaFree(dev_c);cudaFree(dev_a);cudaFree(dev_b);return cudaStatus;
}
复制到删除内容的kernel文件中,点击执行,显示以下界面即为成功:
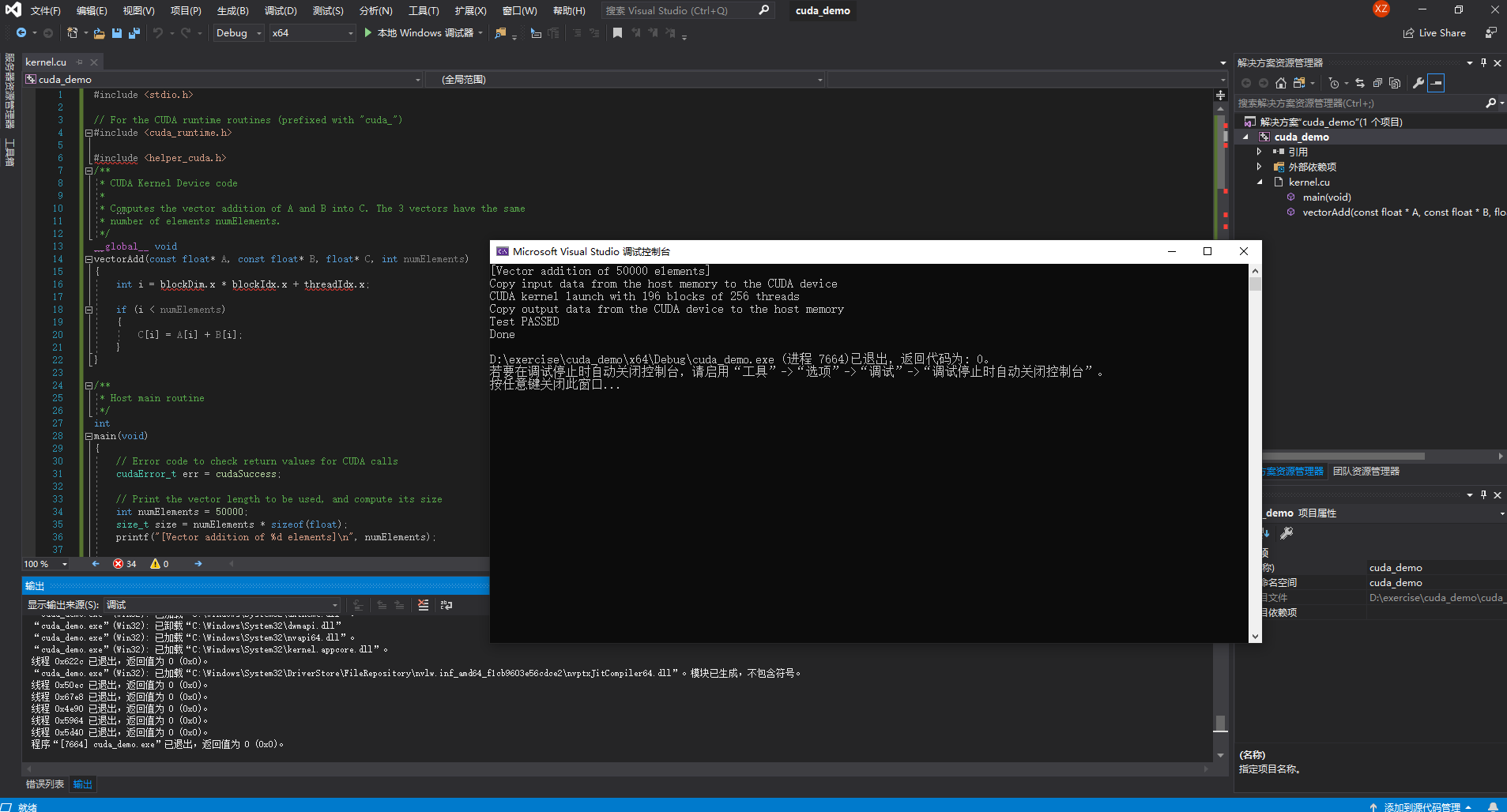
样例1问题:找不到helper_cuda.h文件
但是事情总没有那么简单,遇到了很常见的一个问题:找不到helper_cuda.h文件,解决方案:
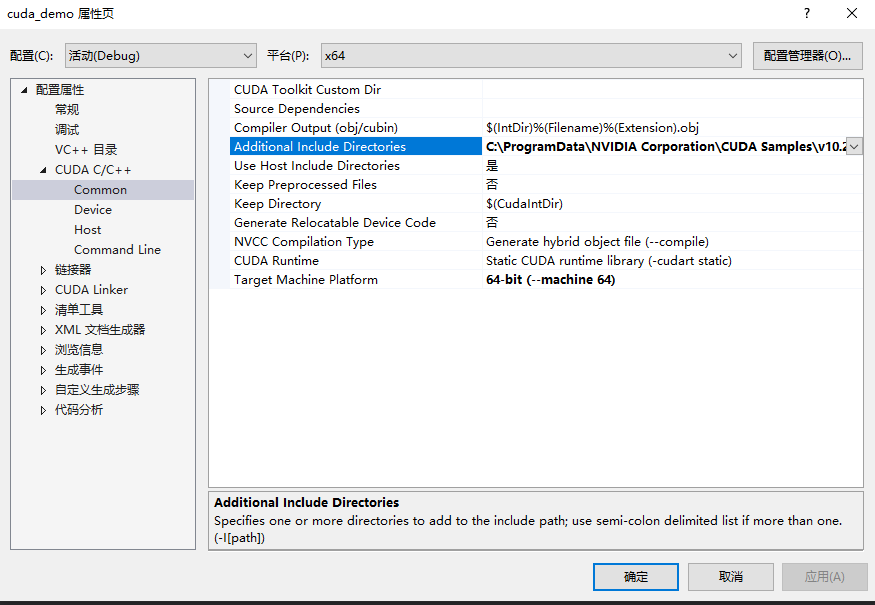
右键cuda项目——属性——配置属性——C/C++——常规——附加包含目录(版本不同,这个结构可能为英文,如我的2019版本界面)
在附加包含目录里添加helper_cuda.h的地址,这里默认安装的地址为
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2\common\inc
类似的
还遇到了一个狗血的bug,就是加入了目录还是无法找到文件,找了很多方式,最后发现重启一下软件就好了。所以上面的一系列配置,如果配置好还发现有bug,记得先关掉重新打开试试。
测试样例2
这是一个打印电脑配置的程序
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include int main() {int deviceCount;cudaGetDeviceCount(&deviceCount);int dev;for (dev = 0; dev < deviceCount; dev++){int driver_version(0), runtime_version(0);cudaDeviceProp deviceProp;cudaGetDeviceProperties(&deviceProp, dev);if (dev == 0)if (deviceProp.minor = 9999 && deviceProp.major == 9999)printf("\n");printf("\nDevice%d:\"%s\"\n", dev, deviceProp.name);cudaDriverGetVersion(&driver_version);printf("CUDA驱动版本: %d.%d\n", driver_version / 1000, (driver_version % 1000) / 10);cudaRuntimeGetVersion(&runtime_version);printf("CUDA运行时版本: %d.%d\n", runtime_version / 1000, (runtime_version % 1000) / 10);printf("设备计算能力: %d.%d\n", deviceProp.major, deviceProp.minor);printf("Total amount of Global Memory: %u bytes\n", deviceProp.totalGlobalMem);printf("Number of SMs: %d\n", deviceProp.multiProcessorCount);printf("Total amount of Constant Memory: %u bytes\n", deviceProp.totalConstMem);printf("Total amount of Shared Memory per block: %u bytes\n", deviceProp.sharedMemPerBlock);printf("Total number of registers available per block: %d\n", deviceProp.regsPerBlock);printf("Warp size: %d\n", deviceProp.warpSize);printf("Maximum number of threads per SM: %d\n", deviceProp.maxThreadsPerMultiProcessor);printf("Maximum number of threads per block: %d\n", deviceProp.maxThreadsPerBlock);printf("Maximum size of each dimension of a block: %d x %d x %d\n", deviceProp.maxThreadsDim[0],deviceProp.maxThreadsDim[1],deviceProp.maxThreadsDim[2]);printf("Maximum size of each dimension of a grid: %d x %d x %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]);printf("Maximum memory pitch: %u bytes\n", deviceProp.memPitch);printf("Texture alignmemt: %u bytes\n", deviceProp.texturePitchAlignment);printf("Clock rate: %.2f GHz\n", deviceProp.clockRate * 1e-6f);printf("Memory Clock rate: %.0f MHz\n", deviceProp.memoryClockRate * 1e-3f);printf("Memory Bus Width: %d-bit\n", deviceProp.memoryBusWidth);}return 0;
}
执行可以得到:
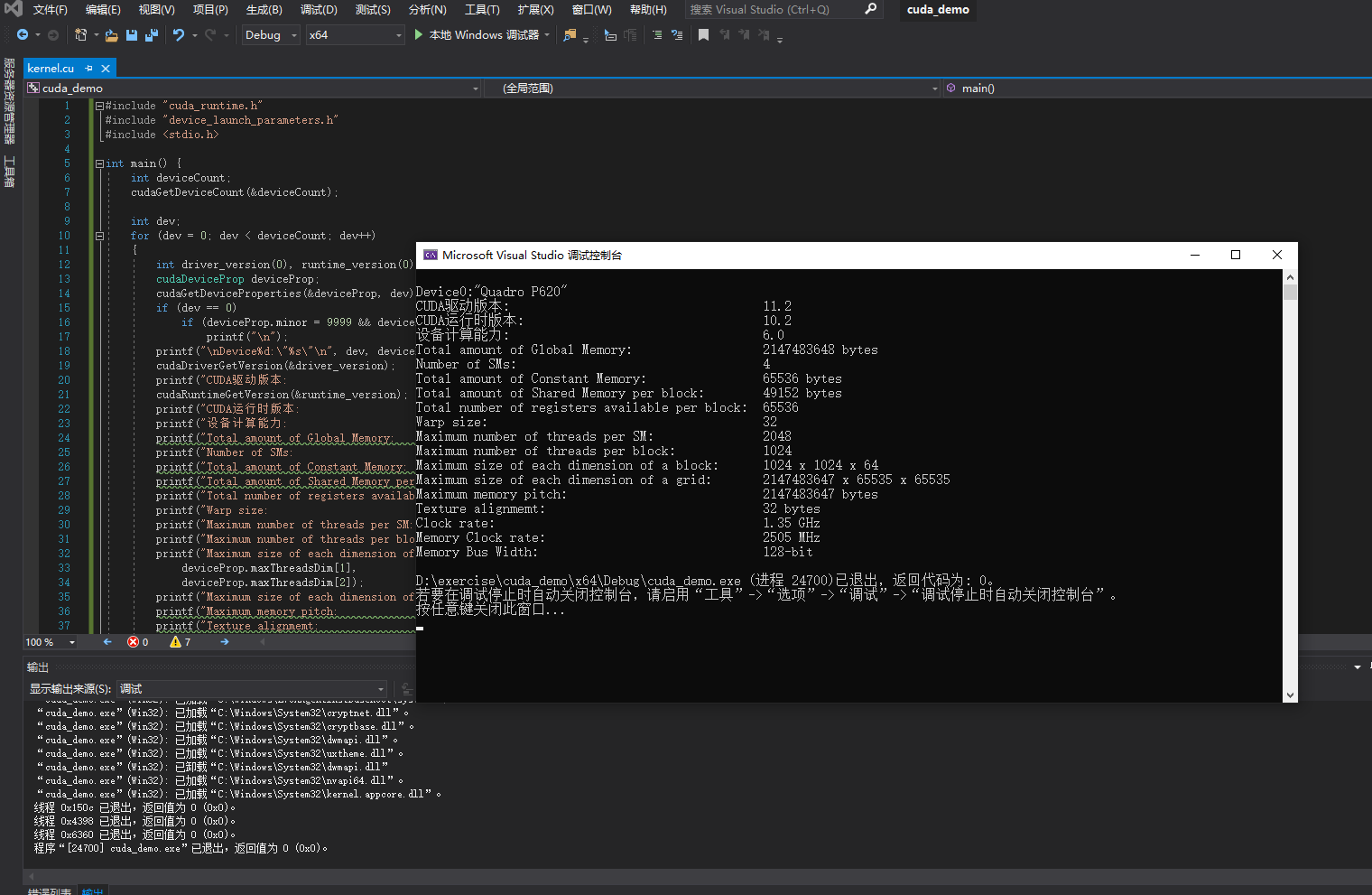
初次执行也遇到了一些问题,后来发现是之前的库没有配置好,有bug的话可以重新建立工程配置试试。
测试样例3
待更新