区分度评估指标-KS
1.背景
KS指标来评估模型的区分度(discrimination),风控场景常用指标之一。本文将从区分度的概念、KS的计算方法、业务指导意义、几何解释、数学思想等多个维度展开分析,以期对KS指标有更为深入的理解认知。
Part 1. 直观理解区分度的概念
在探索性数据分析(EDA)中,若想大致判断自变量x对于因变量y有没有区分度,我们常会分正负样本群体来观察该变量的分布差异,如图1所示。那么,如何判断自变量是有用的?直观理解,如果这两个分布的重叠部分越小,代表正负样本的差异性越大,自变量就能把正负样本更好地区分开。
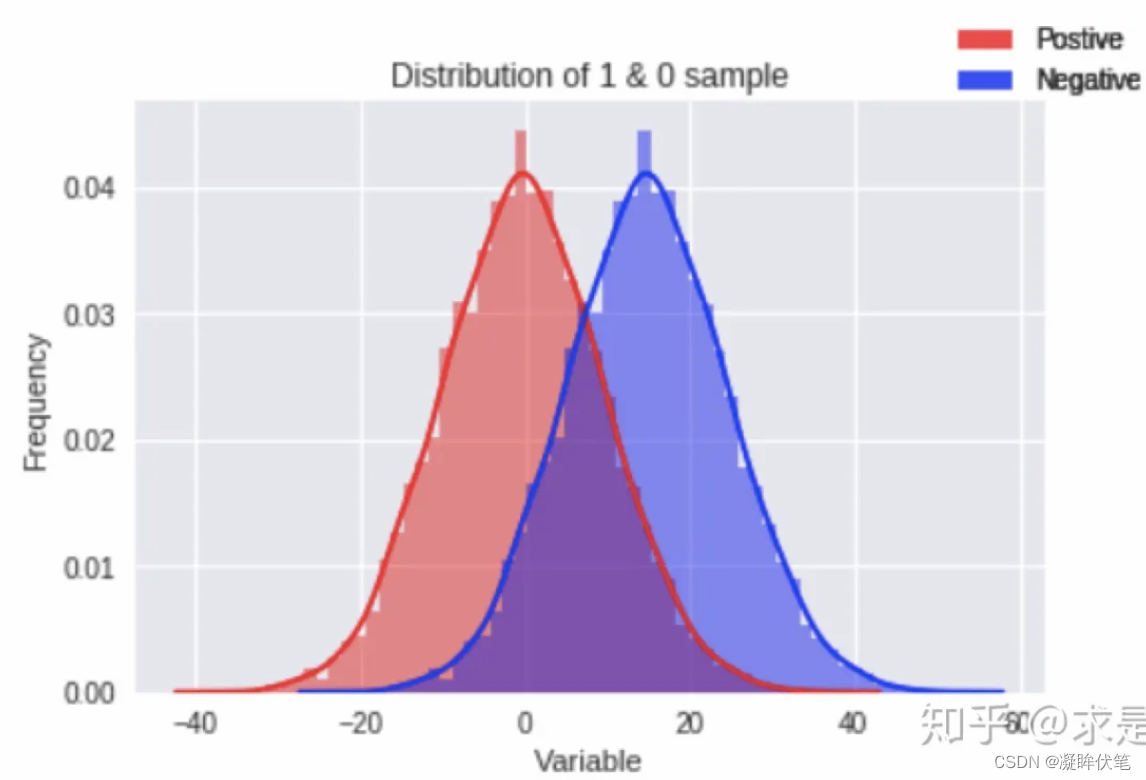
图 1 - 正负样本变量分布差异对比
Part 2. KS统计量的定义
KS(Kolmogorov-Smirnov)统计量由两位苏联数学家A.N. Kolmogorov和N.V. Smirnov提出。在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力(ranking ability)越强。
KS统计量是基于经验累积分布函数(Empirical Cumulative Distribution Function,ECDF)
建立的,一般定义为:
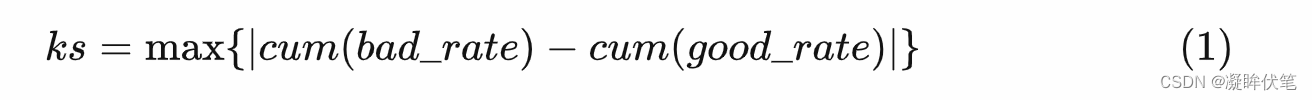
Part 3. KS的计算过程及业务分析
很多博客文章告诉我们,计算KS的常见方法是这样的:
- step 1. 对变量进行分箱(binning),可以选择等频、等距,或者自定义距离。
- step 2. 计算每个分箱区间的好账户数(goods)和坏账户数(bads)。
- step 3. 计算每个分箱区间的累计好账户数占总好账户数比率(cum_good_rate)和累计坏账户数占总坏账户数比率(cum_bad_rate)。
- step 4. 计算每个分箱区间累计坏账户占比与累计好账户占比差的绝对值,得到KS曲线。也就是: ks=|cum_goodrate−cum_badrate|
- step 5. 在这些绝对值中取最大值,得到此变量最终的KS值。
为帮助大家理解,现以具体数据(非业务数据)展示这一过程,如图2所示。其中,total是每个分数区间里的样本量,total_rate为样本量占比;bad代表逾期,bad_rate为每个分数区间里的坏样本占比。

图 2 - KS计算过程表
那么,分析这张表我们可以得到哪些信息呢?
- 模型分数越高,逾期率越低,代表是信用评分。因此,低分段bad rate相对于高分段更高, cum_bad_rate曲线增长速率会比cum_good_rate更快,cum_bad_rate曲线在cum_good_rate上方。
- 每个分箱里的样本数基本相同,说明是等频分箱。分箱时需要考虑样本量是否满足统计意义。
- 若我们设定策略cutoff为0.65(低于这个值的用户预测为bad,将会被拒绝),查表可知低于cutoff的cum_bad_rate为82.75%,那么将拒绝约82.75%的坏账户。
- 根据bad_rate变化趋势,模型的排序性很好。如果是A卡(信用评分),那么对排序性要求就比较高,因为需要根据风险等级对用户风险定价。
- 模型的KS达到53.1%,区分度很强。这是设定cutoff为0.65时达到的最理想状态。实际中由于需权衡通过率与坏账率之间的关系,一般不会设置在理想值。因此,KS统计量是好坏距离或区分度的上限。
- 通常情况下,模型KS很少能达到52%,因此需要检验模型是否发生过拟合,或者数据信息泄漏 。
KS值的取值范围是[0,1],一般习惯乘以100%。通常来说,KS越大,表明正负样本区分程度越好。KS的业务评价标准如图3所示。由于理解因人而异,不一定完全合理,仅供参考。
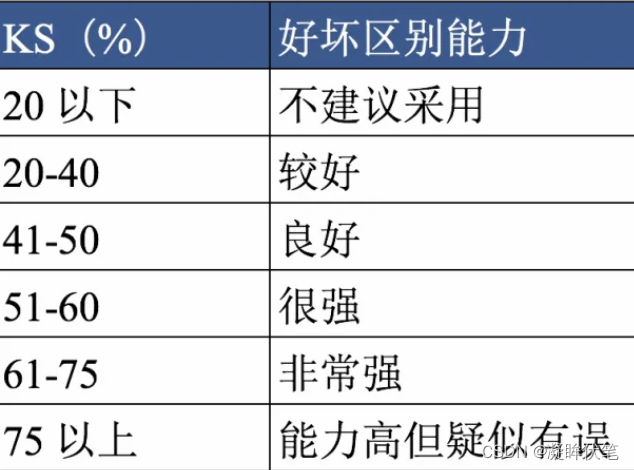
图 3 - KS的评价标准(供参考)
需要指出的是,KS是在放贷样本上评估的,放贷样本相对于全量申贷样本永远是有偏的。如果风控系统处于裸奔状态(相当于不生效,随机拒绝),那么这个偏差就会很小;反之,如果风控系统做得越好,偏差就会越大。因此,KS不仅仅只是一个数值指标,其背后蕴藏着很多原因,值得我们结合业务去认真分析。
当KS不佳时,为了达到KS的预期目标,我们可以从哪些方面着手去优化呢?一般建议如下:
- 检验入模变量是否已经被策略使用,使用重复变量会导致区分度不高。
- 检验训练样本与验证样本之间的客群差异是否变化明显?样本永远是统计学习中的重要部分。
- 开发对目标场景更具针对性的新特征。比如,识别长期信用风险,就使用一些强金融属性变量;识别欺诈风险,就使用一些短期负面变量。
- 分群建模或分群测算。分群需要考虑稳定性和差异性。
- bad case分析,提取特征。
若将表2数据可视化,就可以得到我们平时常见的KS曲线图(也叫鱼眼图 ),其中横坐标为模型概率分数(0~1),纵坐标为百分比(0~100%)。红色曲线代表累计坏账户占比,绿色曲线代表累计好账户占比,蓝色曲线代表KS曲线。

至此,我们已经基本了解KS的计算流程、评价标准、业务指导意义和优化思路。接下来,再给大家留下几个思考题 :
- 为什么风控中常用KS指标来评价模型效果,而不用准确率、召回率等?
- 最大KS值只是一个宏观结果,那么在不同cutoff内取到max时,模型性能有什么差异?
- 一般情况下,KS越大越好,但为什么通常认为高于75%时就不可靠?
Part 4. 风控中选用KS指标的原因分析
风控建模时,我们常把样本标签分为GBIX四类,其中:G = Good(好人,标记为0),B = Bad(坏人,标记为1),I = Indeterminate (不定,未进入表现期),X = Exclusion(排斥,异常样本)。
需要指出的是,Good和Bad之间的定义往往是模糊、连续的,依赖于实际业务需求。这里举两个例子或许能帮助大家理解:
例1:模糊性
对于12期信贷产品,如果设定表现期为前6期,S6D15(前6期中任意一期逾期超过15天)就是1,否则为0;但是后来如果把表现期调整为前3期,那么对于“前3期都正常还款,但4~6期才发生逾期并超过15天“的这部分样本而言,原本所定义的label就从1就变成0了。
因此,业务需求的不同,导致标签定义不是绝对的。
例2:连续性
定义首期逾期超过30天为1,否则为0。但是,逾期29天和逾期31天的用户之间其实并没有不可跨越的硬间隔,逾期29天的用户可能会进一步恶化为逾期31天。
由于逾期的严重程度定义本身就带有一定的主观性,我们很难说逾期天数差几天有多少本质的差异,所以哪怕我们为了转化为分类问题做了硬性的1和0的界限定义,但在业务上理解还是一个连续问题。
因此在风控中,y的定义并不是非黑即白(离散型),而用概率分布(连续型)来衡量或许更合理。
我们通常用概率分布来描述这种模糊的软间隔概念,也倾向于使用LR这种概率模型,而不是SVM这种以边界距离作为优化目标的模型。
那为什么选择KS指标呢?——KS指标倾向于从概率角度衡量正负样本分布之间的差异。正是因为正负样本之间的模糊性和连续性,所以KS也是一条连续曲线。但最终为什么取一个最大值,主要原因是提取KS曲线中的一个显著特征,从而便于相互比较。
Part 5. ROC曲线的几何绘制及理解
在风控场景中,样本不均衡问题非常普遍,一般正负样本比都能达到1:100甚至更低。此时,评估模型的准确率是不可靠的。因为只要全部预测为负样本,就能达到很高的准确率。例如,如果数据集中有95个猫和5个狗,分类器会简单的将其都分为猫,此时准确率是95%。
【此处注意,平时都说样本比例不影响auc,这个说法有问题,在样本比例不极端的情况下,不影响auc。但是如果样本比例极端的情况下,TPR个FPR曲线很极端,这样的auc意义不大,所以样本比例还是影响auc的】
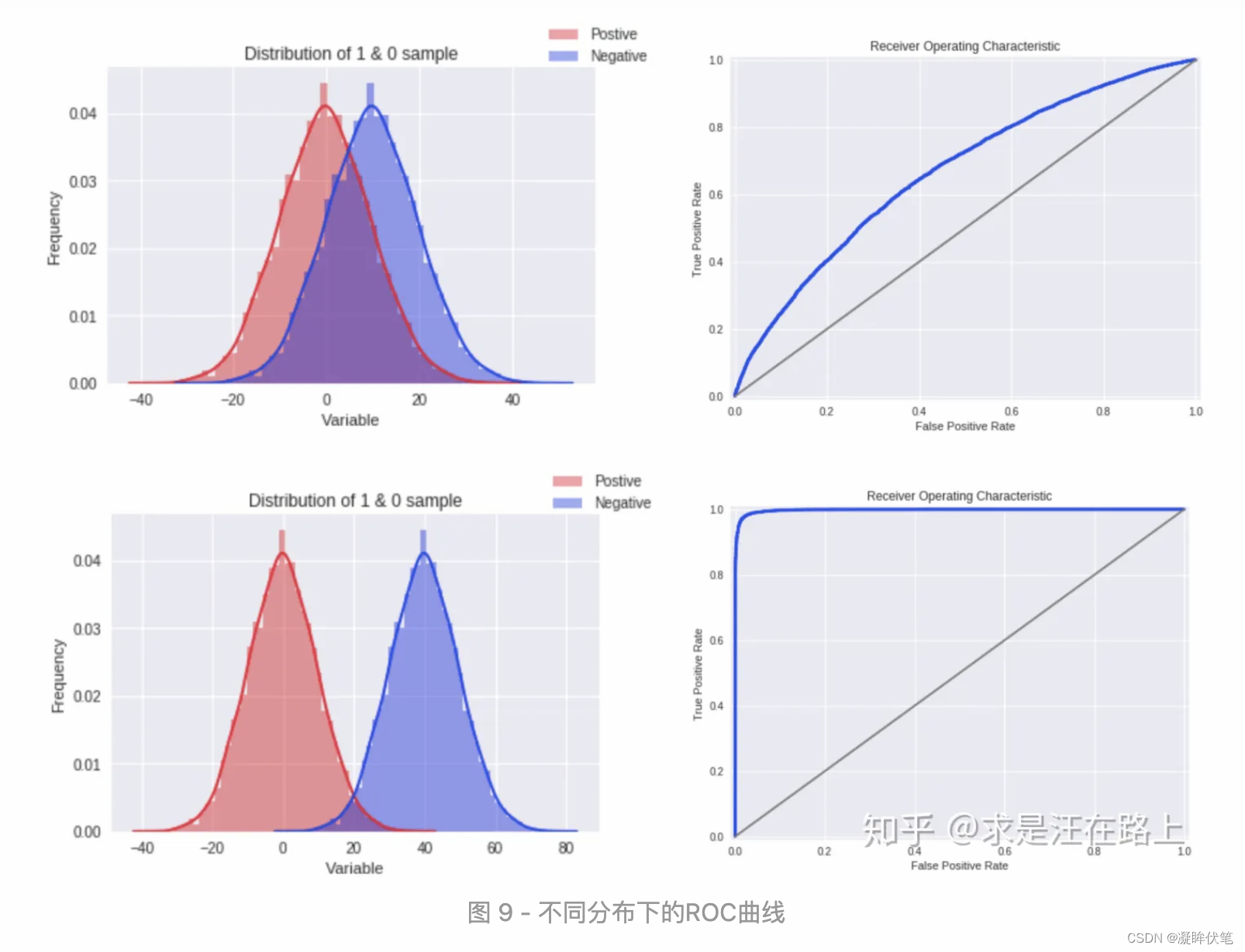
在理解KS和ROC曲线的关系后,我们也就更容易理解——为什么通常认为KS在高于75%时就不可靠?我们可以想象,如果KS达到80%以上,此时ROC曲线就会变得很畸形,如图9所示。
另一个更重要的可能原因是,为了便于制定策略,模型评分在放贷样本上一般要求服从正态分布。现实中不太可能出现如此完美的分类器,如果出现这种明显的双峰分布,反而就不合常理,我们就有理由怀疑其可靠性。( 值得一起探讨)
Part 8. KS的计算代码(Python)
def ks_compute(proba_arr, target_arr):'''----------------------------------------------------------------------功能:利用scipy库函数计算ks指标----------------------------------------------------------------------:param proba_arr: numpy array of shape (1,), 预测为1的概率.:param target_arr: numpy array of shape (1,), 取值为0或1.----------------------------------------------------------------------:return ks_value: float, ks score estimation----------------------------------------------------------------------示例:>>> ks_compute(proba_arr=df['score'], target_arr=df[target])>>> 0.5262199213881699----------------------------------------------------------------------'''from scipy.stats import ks_2sampget_ks = lambda proba_arr, target_arr: ks_2samp(proba_arr[target_arr == 1], \proba_arr[target_arr == 0]).statisticks_value = get_ks(proba_arr, target_arr)return ks_value
参考:
1.风控模型—区分度评估指标(KS)深入理解应用 - 知乎
2.