python简单实现网络爬虫
前言
在这一篇博客中,我会用python来实现一个简单的网络爬虫。简单的爬取一下一些音乐网站、小说网站的标题、关键字还有摘要!所以这个爬虫并不是万能爬,只针对符合特定规则的网站使用。(只使用于爬标题、关键字和摘要的,所以只能爬在head标签中这三个信息都有的且meta标签中name参数在本文信息前面的网站。)希望大家看了这篇博客,能对大家学习爬虫有些帮助!(并不是很高深的爬虫,很基础!!!)
要用到的知识
要用到的知识都是比较简单的啦,基本上花点时间都能学会。
首先就是python的基础语法啦,会用能看懂就好。(会有一些文件读取的操作)
还有就是关于爬虫的一些知识了:贪婪匹配和惰性匹配(re解析方式解析网页源代码)
还需要一丢丢前端的知识:只需要大概看得懂html源代码就行(知道是在干嘛的)
这些就差不多了(b站是最好的大学(主要是我懒,也没时间写这些))
爬虫的具体实现
先拿一个网站做例子分析,打开酷狗官网,右键点击检查:
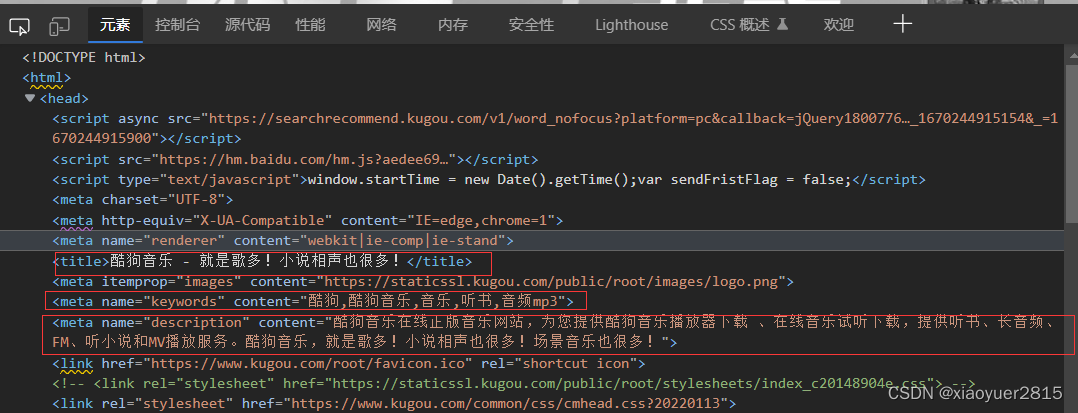
红框中的就是我们需要提取的信息啦。这还是很容易提取出来的。使用re模块里面的贪婪匹配与惰性匹配,将想要的数据提取出来就好。例如:
obj = re.compile(r'(?P.*?) .*?'r'.*?)".*?>'r'.*?)".*?>', re.S) 在上面我们只用了一次compile函数就完成了匹配。
但是我,我们需要提取的并不止是酷狗官网,还有其他一些网站。上面代码写的规则并不适合一些网站,比如,一些网站把标题放在最后面,关键字和摘要放在前面,那么我们就匹配不到想要的信息。这个也比较好解决,将一条compile拆成多条compile就行。
obj1 = re.compile(r'(?P.*?) ', re.S)obj2 = re.compile(r'.*?)".*?>', re.S)obj3 = re.compile(r'.*?)".*?>', re.S) 下面是整个python源代码(在源代码里面使用了文件读取将提取到的信息保存到文件里面):
import requests
import re
import csvurls = []# 分别是酷狗音乐、酷我音乐、网易云音乐、起点中文网、咪咕音乐、bilibili、qq音乐
urls.append("https://www.kugou.com/")
urls.append("http://www.kuwo.cn/")
urls.append("https://music.163.com/")
urls.append("https://www.qidian.com/")
urls.append("https://www.migu.cn/index.html")
urls.append("https://www.bilibili.com/")
urls.append("https://y.qq.com/")# 打开csv文件
f = open("test.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
csvwriter.writerow(["标题","关键字","摘要"])# 对所有网站进行get访问,获取源代码后用re模块将想要提取的内容提取出来
for url in urls:# 向网页发出请求resp = requests.get(url)# 设置字符编码resp.encoding = 'utf-8'# 使用非贪婪匹配.*?(惰性匹配),re.S用来匹配换行符obj1 = re.compile(r'(?P.*?) ', re.S)obj2 = re.compile(r'.*?)".*?>', re.S)obj3 = re.compile(r'.*?)".*?>', re.S)# 对网页源代码进行匹配result1 = obj1.finditer(resp.text)result2 = obj2.finditer(resp.text)result3 = obj3.finditer(resp.text)# 创建一个队列来将数据保存,方便写入csv文件中lis = []for it in result1:#print("标题:",it.group("title"))lis.append(it.group("title"))for it in result2:#print("关键字:",it.group("keywords"))lis.append(it.group("keywords"))for it in result3:#print("摘要:",it.group("description"))lis.append(it.group("description"))print(lis)print()# 将队列写入csv文件csvwriter.writerow(lis)# 关闭请求resp.close()
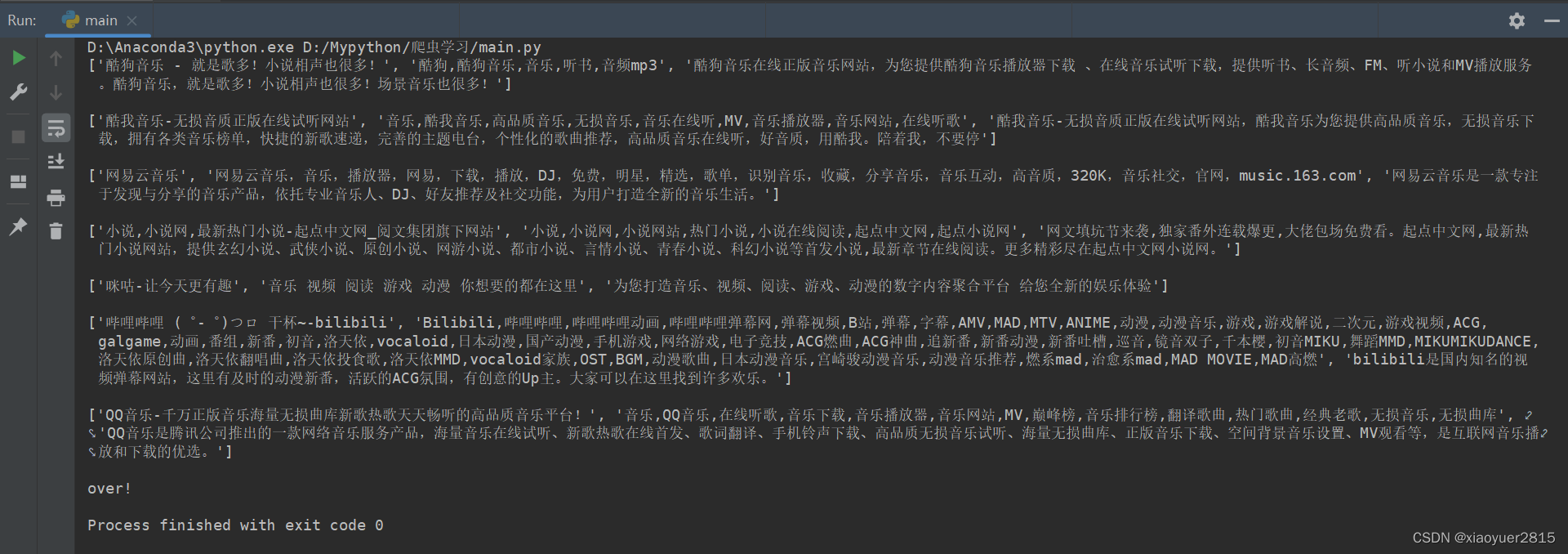
print('over!')
# 关闭文件指针
f.close() 下面是运行结果图:
用WPS打开这个csv文件进行查看:

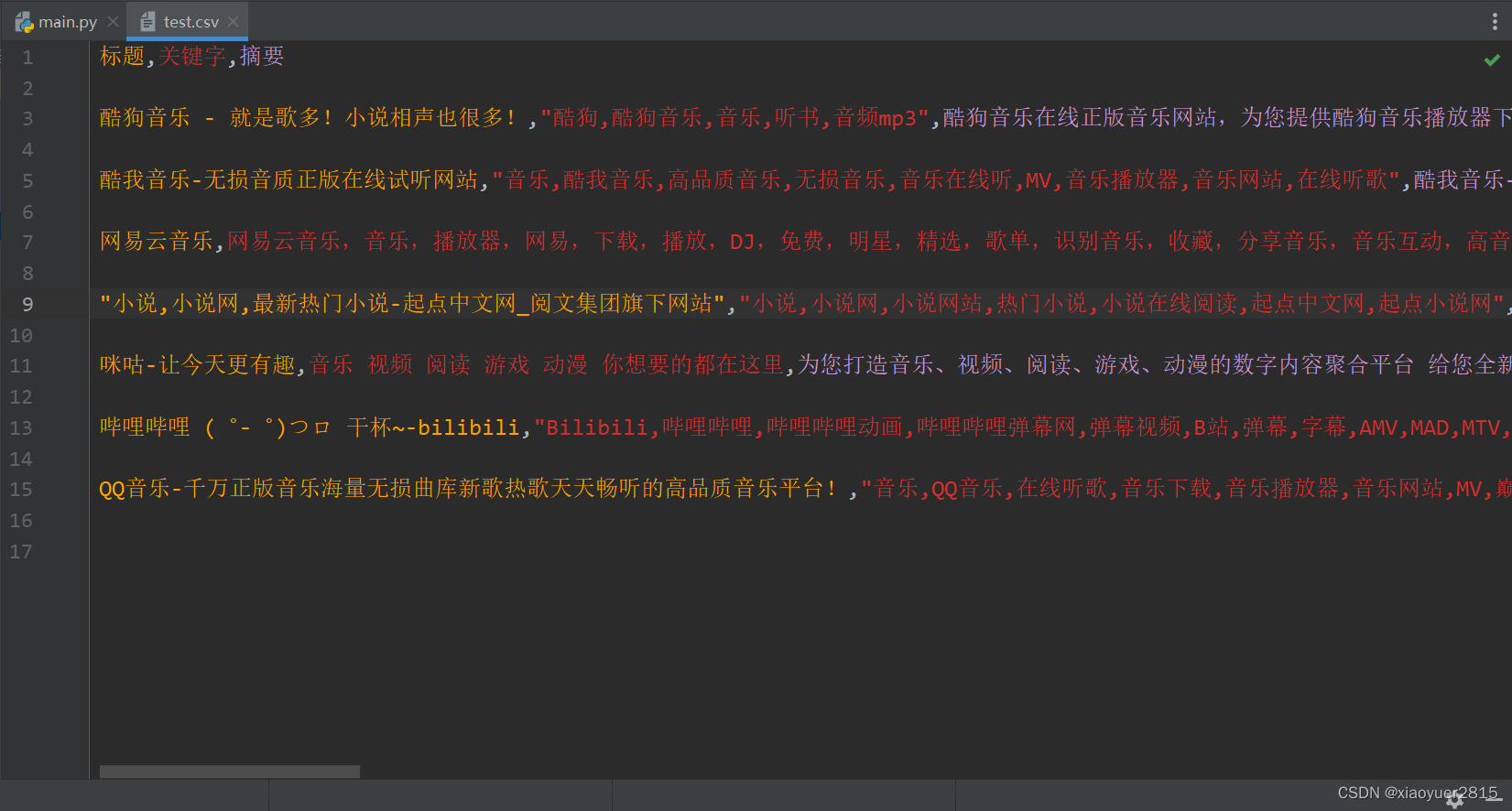
在pycharm中打开csv文件查看是否将数据写入文件中:
结语
好矛盾好纠结,又想把思路写清楚又感觉没必要。。。。。。
感谢浏览这篇博客,希望这篇博客的内容能对你有帮助。