mongodb整合springbootQ
SpringBoot整合MongoDB_一个冬天的童话的博客-CSDN博客_mongodb的依赖SpringBoot整合MongoDB的过程 https://blog.csdn.net/m0_53563908/article/details/1268980981,环境配置
https://blog.csdn.net/m0_53563908/article/details/1268980981,环境配置
1.引入依赖
org.springframework.boot spring-boot-starter-data-mongodb 2.配置yml
spring:data:mongodb:uri: mongodb://localhost:27017/test?authSource=admin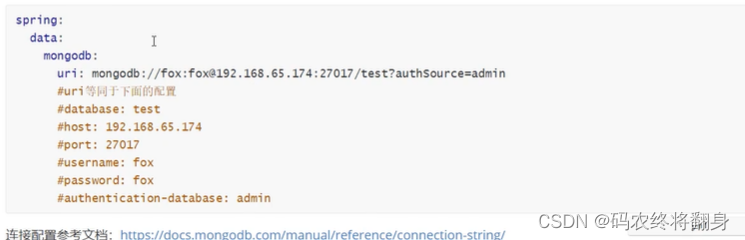
3.使用时注入mongoTemplate
@Autowired
private MongoTemplate mongoTemplate;2 集合操作
package com.example.mongodb01;import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.mongodb.core.MongoTemplate;@SpringBootTest
class Mongodb01ApplicationTests {@AutowiredMongoTemplate mongoTemplate;/** 创建集合* */@Testpublic void testCreateCollection(){boolean emp = mongoTemplate.collectionExists("emp");if(emp){//删除集合mongoTemplate.dropCollection("emp");}//创建集合mongoTemplate.createCollection("emp");}}
3.文档操作
相关注解

创建实体
package com.example.mongodb01.entity;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import org.springframework.data.mongodb.core.mapping.Field;import java.util.Date;/*** @ProjectName: mongodb01* @packageName: com.example.mongodb01.entity* @author: xmhz45* @create: 2022/12/3 18:37*/
@Document("emp")//对应emp集合中的一个文档
@Data
@AllArgsConstructor
@NoArgsConstructor
public class EmpLoyee {@Id //映射文档中的_idprivate Integer id;@Field("username")private String name;@Fieldprivate int age;@Fieldprivate Double salary;@Fieldprivate Date birthday;
}
添加文档
insert方法返回值是新增的Document对象,里面包含了新增后id的值。如果集合不存在会自动创建集合通过Spring Data MongoDB会给集合中多加一个class的属性,存储新增时Document对应)ava中类的全限定路径,这么做为了查询时能把Document转换为Java类型。
/*** 添加文档*/@Testpublic void testInsert(){EmpLoyee empLoyee = new EmpLoyee(1,"小王",30,10000.0,new Date());System.out.println("1");//添加文档//save: _id存在时更新数据//mongoTemplate.save(employee);//insert: _id存在抛出异常 支持批量操作mongoTemplate.insert(empLoyee);List list = Arrays.asList(new EmpLoyee(2,"张三1",21,5000.0,new Date()),new EmpLoyee(3,"张三2",22,6000.0,new Date()),new EmpLoyee(4,"张三3",23,7000.0,new Date()));//插入多条数据mongoTemplate.insert(list,EmpLoyee.class);} 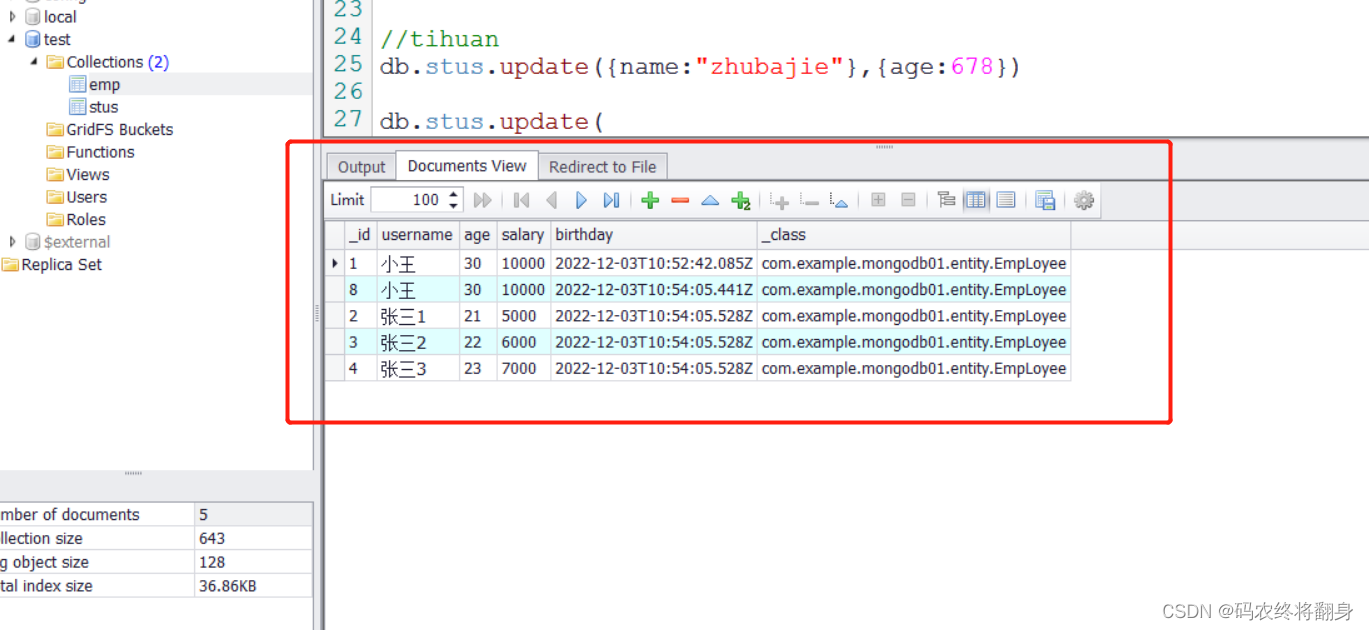
查询文档
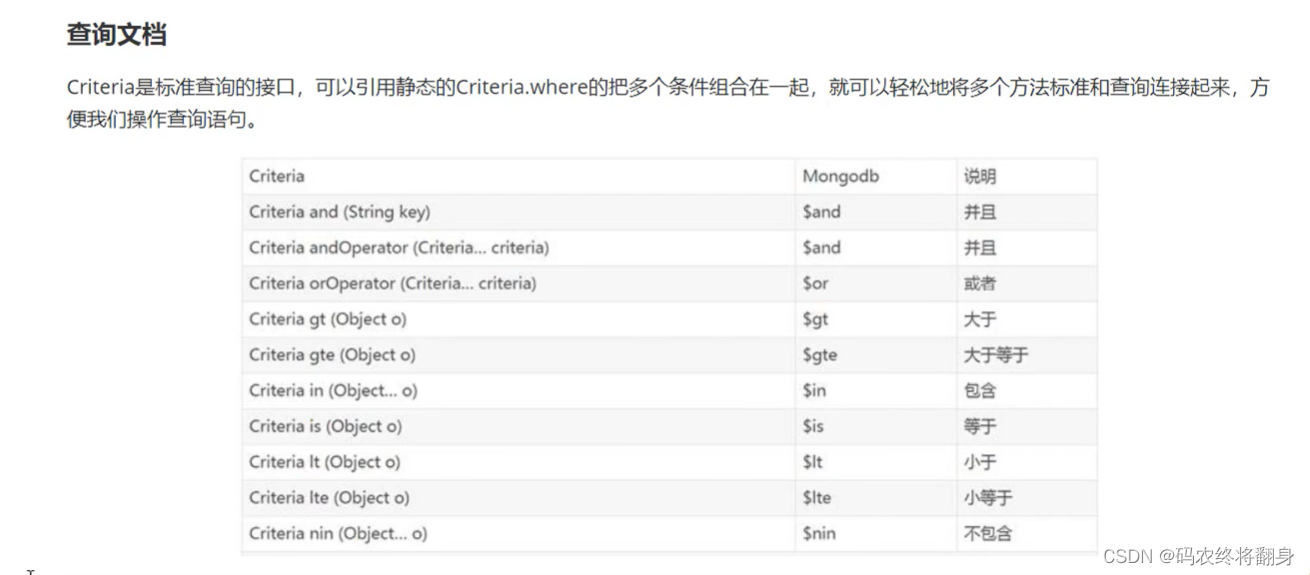
@Testpublic void testFind(){System.out.println("===========查看所有文档===========");//查看所有文档List list = mongoTemplate.findAll(EmpLoyee.class);list.forEach(System.out::println);System.out.println("===========findOne返回第一个文档===========");//如果查询结果是多个,返回其中第一个文档对象EmpLoyee one = mongoTemplate.findOne(new Query(), EmpLoyee.class);System.out.println(one);System.out.println("===========根据_id查询===========");EmpLoyee e = mongoTemplate.findById(1, EmpLoyee.class);System.out.println(e);System.out.println("===========条件查询===========");//new Query() 表示没有条件//查询薪资大于等于8000的员工//Query query = new Query(Criteria.where("salary").gte(8000));//查询薪资大于4000小于10000的员工//Query query = new Query(Criteria.where("salary").where("salary").gt(4000).lt(10000));//正则查询(模糊查询) java中正则不需要有////Query query = new Query(Criteria.where("name").regex("王"));//and or 多条件查询Criteria criteria = new Criteria();//and 查询年龄大于25&薪资大于8000的员工//criteria.andOperator(Criteria.where("age").gt(25),Criteria.where("salary").gt(8000));//or 查询姓名是张三或者薪资大于8000的员工criteria.orOperator(Criteria.where("name").is("张三1"),Criteria.where("salary").gt(8000));Query query = new Query(criteria);//sort排序//query.with(Sort.by(Sort.Order.desc("salary")));//skip limit 分页 skip用于指定跳过记录数 limit则用于限定返回结果数量query.with(Sort.by(Sort.Order.desc("salary"))).skip(0) //指定跳过记录数.limit(4); //每页显示记录数//查询结果List empLoyees = mongoTemplate.find(query,EmpLoyee.class);empLoyees.forEach(System.out::println);} 使用json字符串格式查询

更新文档
在Mongodb中无论是使用客户端API还是使用Spring Data,更新返回结果一定是受行数影响,如果更新后的结果和更新前的结果是相同,返回0。
。updateFirst() 只更新满足条件的第一条记录
。 updateMulti() 更新所有满足条件的记录
。 upsert0 没有符合条件的记录则插入数据
@Testpublic void testUpdate(){//query设置查询条件Query query = new Query(Criteria.where("salary").gte(7000));System.out.println("==========更新前==========");List empLoyees = mongoTemplate.find(query, EmpLoyee.class);empLoyees.forEach(System.out::println);Update update = new Update();//设置更新属性update.set("salary",18000);//updateFirst() 只更新满足条件的第一条记录//UpdateResult updateResult = mongoTemplate.updateFirst(query, update, EmpLoyee.class);//updateMulti() 更行所有满足条件的记录UpdateResult updateResult = mongoTemplate.updateMulti(query, update, EmpLoyee.class);//upsert() 没有符合条件的记录则插入数据//update.setOnInsert("id",11);//指定_id//UpdateResult updateResult = mongoTemplate.upsert(query, update, EmpLoyee.class);//返回修改的记录数System.out.println(updateResult.getModifiedCount());System.out.println("=============更新后============");empLoyees = mongoTemplate.find(query, EmpLoyee.class);empLoyees.forEach(System.out::println);} 删除文档
@Testpublic void testDelete(){//删除所有文档 不如用dropCollection()//mongoTemplate.remove(new Query(),EmpLoyee.class);//条件删除Query query = new Query(Criteria.where("salary").gte(10000));mongoTemplate.remove(query,EmpLoyee.class);}4.聚合操作
聚合提作处理数据记录并返回计算结果(诸如统计平均值,求和等)。聚合提作组值来自多个文档,可以对分组数据执行各种提作以返回单个结果。聚合操作包含三类: 单一作用聚合、聚合管道、MapReduce。
- 单一作用聚合:提供了对常见聚合过程的简单访问,提作都从单个集合聚合文档.
- 聚合管道是一个数据聚合的框架,模型基于数据处理流水线的概念。文档进入多级管道,将文档转换为聚合结果
- MapReduce提作具有两个阶段:处理每个文档并向每个输入文档发射一个或多个对象的map阶段,以及reduce组合map操作的输出阶段。
4.1单一作用聚合
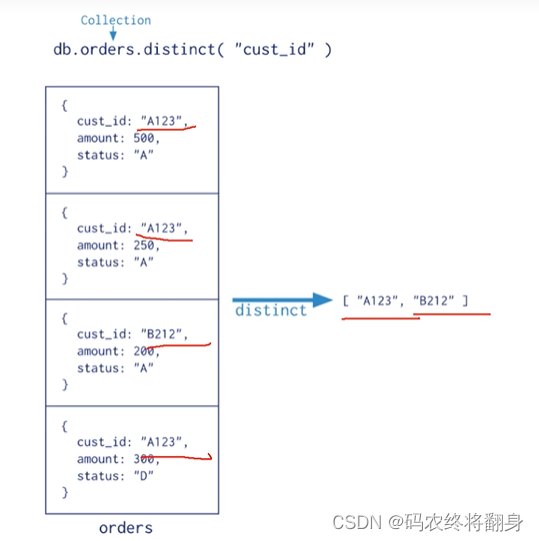
MongoDB提供 db.collection.estimatedDocumentCount()[忽略查询条件];db.collection.count(),db.collection.distinct() 这类单一作用的聚合函数。所有这些操作都聚合来自单个集合的文档,虽然这些操作提供了对公共聚合过程的简单访问,但它们缺乏聚合管道和map-Redue的灵活性和功能

4.2 聚合管道
什么是 MongoDB 聚合框架
MongoDB 聚合框架 (Aggregation Framework) 是一个计算框架,它可以:
- 作用在一个或几个集合上;
- 对集合中的数据进行的一系列运算;
- 将这些数据转化为期望的形式;
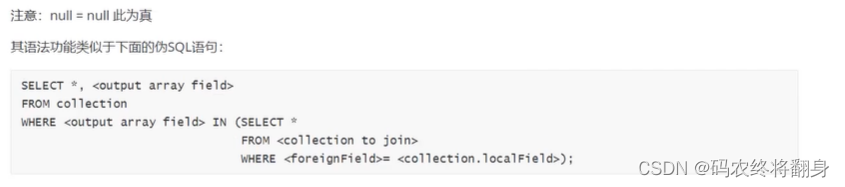
从效果而言,聚合框架相当于 SQL 查询中的GROUP BY、 LEFT OUTER JOIN、 AS等
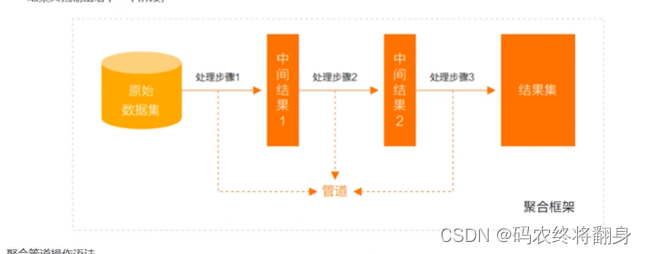
管道 (Pipeline) 和阶段 (Stage)
整个聚合运算过程称为管道 (Pipeline) ,它是由多个阶段 (Stage) 组成的,每个管道:
- 接受一系列文档(原始数据) ;
- 每个阶段对这些文档进行一系列运算;
- 结果文档输出给下一个阶段;
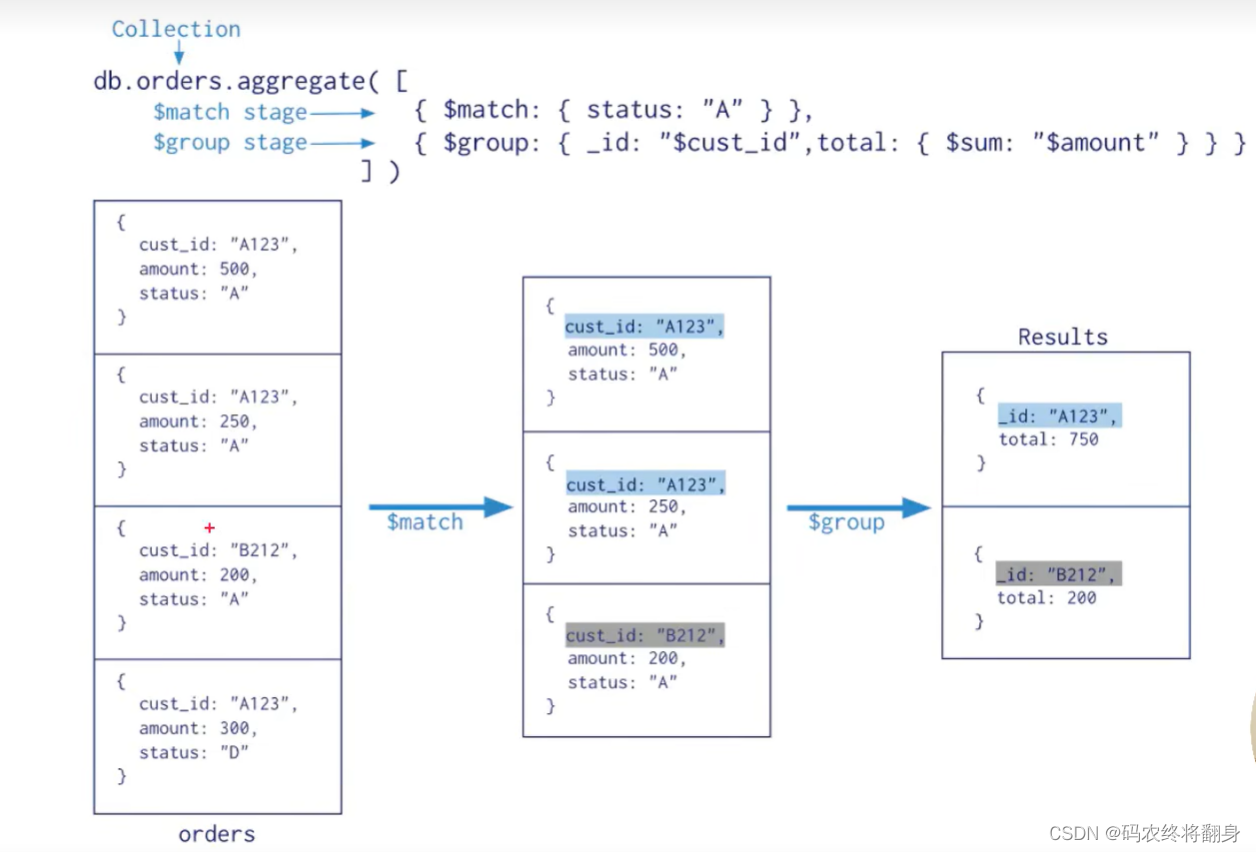
聚合管道操作语法
pipeline = [$stage1, $stage2,...$stageN];
db .collection .aggregate(pipeline,{options})
- pipelines 一组数据聚合阶段。除$out、$Merge和$geonear阶段之外,每个阶段都可以在管道中出现多次。
- options 可选,聚合操作的其他参数。包含: 查询计划、是否使用临时文件、游标、最大操作时间、读写策路、强制索引等等
常用的管道聚合阶段
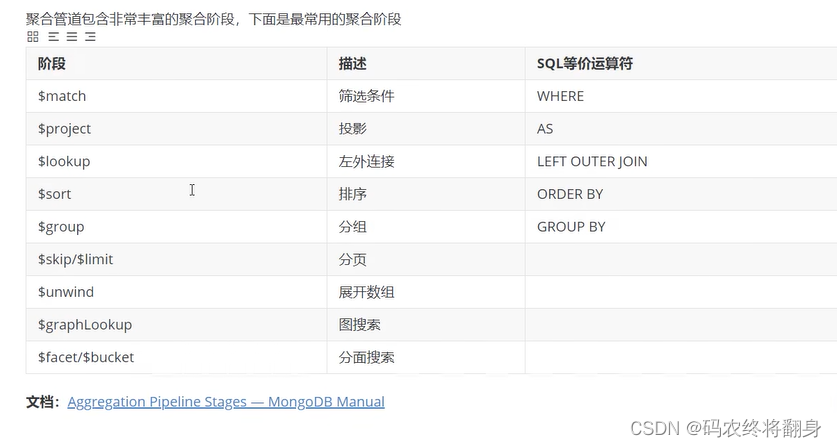
数据准备
准备数据集,执行脚本
var tags = ["nosql", "mongodb" , "document" , "developer" , "popular"];
var types = ["technology","sociality","travel","novel","literature"];
var books=[];
for(var i=0;i<50;i++){var typeIdx = Math.floor(Math.random()*types.length);var tagIdx = Math.floor(Math.random()*tags.length);var tagIdx2 = Math.floor(Math.random()*tags.length);var favCount = Math.floor(Math.random()*100);var username = "xx00"+Math.floor(Math.random()*10);var age = 20 + Math.floor(Math.random()*15);var book = {title:"book-"+i,type: types[typeIdx],tag: [tags[tagIdx],tags[tagIdx2]],favCount: favCount,author: {name :username , age :age}};books.push(book)
}
db.books.insertMany(books);db.books.find().pretty() 显示json格式
$project
投影操作,将原始字段投影成指定名称,如将集合中的 title 投影成 name
db.books.aggregate([{$project: {name:"$title"}}])
$proiect 可以灵活控制输出文档的格式,也可以剔除不需要的字段 0不显示,1显示,默认为0
db.books.aggregate([{$project:{name:"$title",_id:0,type:1,author:1}}])
从嵌套文档中排除字段
db.books.aggregate([
{$project:{name:"$title",_id:0,type:1,"author.name":1}}
])
或者
db.books.aggregate([
{$project:{name:"$title",_id:0,type:1,author:{name:1}}}])
$match
$match用于对文档进行筛选,之后可以在得到的文档子集上做聚合,$match可以使用除了地理空间之外的所有常规查询操作符,在实际应用中尽可能将$match放在管道的前面位置。这样有两个好处:一是可以快速将不需要的文档过滤掉,以减少管道的工作量;二是如果再投射和分组之前执行$match,查询可以使用索引。
db.books.aggregate([{$match:{type:"technology"}}])
db.books.aggregate([{$match:{type:"technology",title:/book-2/}}])
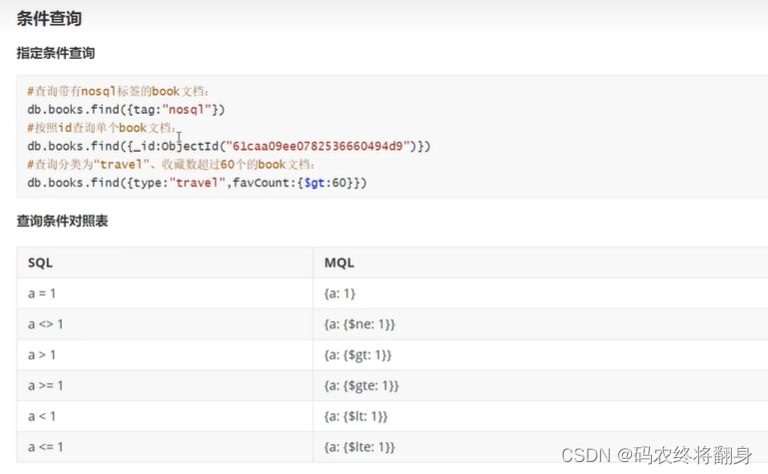

 筛选管道操作和其他管道操作配合时候时,尽量放到开始阶段,这样可以减少后续管道操作符要操作的文档数,提升效率
筛选管道操作和其他管道操作配合时候时,尽量放到开始阶段,这样可以减少后续管道操作符要操作的文档数,提升效率
$count
计数并返回与查询匹配的结果数
db.books.aggregate([{$match:{type:"technology"}},{$count: "type_count"}])
$match阶段筛选出type匹配technology的文档,并传到下一阶段,
$count阶段返回聚合管道中剩余文档的计数,并将该值分配给type_count
$group
按指定的表达式对文档进行分组,并将每个不同分组的文档输出到下一个阶段。输出文档包含一个
_id字段,该字段按键包含不同的组。输出文档还可以包含计算字段,该字段保存由$group的_id字段分组的一些accumulator表达式的值。$group不会输出具体的文档而只是统计信息。
{ $group: { _id:
, : { : },...}}
- id字段是必填的;但是,可以指定id值为null来为整个输入文档计算累计值。
- 剩余的计算字段是可选的,并使用
运算符进行计算。 - _id和
表达式可以接受任何有效的表达式。
accumulator操作符
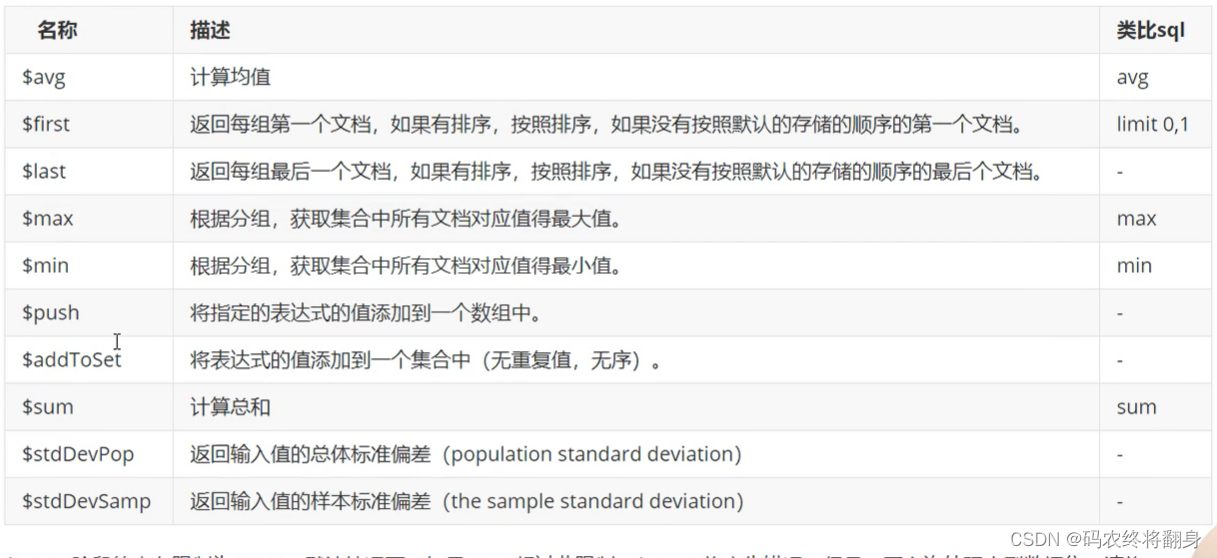
$group阶段的内存限制为100M。默认情况下,如果stage超过此限制,$group将产生错误。但是,要允许处理大型数据集,请将allowDiskUse选项设置为true以启用$group操作以写入临时文件。
book的数量,收藏总数和平均值
db.books.aggregate([
{$group:{_id:null ,count:{$sum:1},pop:{$sum:"$favCount"} ,avg:{$avg:"$favCount"}}}])
统计每个作者的book收藏总数
db.books.aggregate([
{$group:{_id:"$author.name",pop:{$sum:"$favCount"}}}])
统计每个作者的每本book的收藏数
db.books .aggregate([
{$group:{_id: {name:"{author.name",title:"$title"} ,pop:{$sum:"$favCount"}}}])
每个作者的book的type合集
db.books.aggregate([
{$group:{_id:"$author.name",types :{$addToSet:"$type"}}}])
$unwind
可以将数组拆分为单独的文档
v3.2+支持如下语法:
{
$unwind:
{#要指定字段路径,在字段名称前加上$符并用引号括起来。
path:
,
#可选,一个新字段的名称用于存放元素的数组索引。该名称不能以$开头。 includeArrayIndex:,
#可选,default :false,若为true,如果路径为空,缺少或为空数组,则$unwind输出文档preserveNullAndEmptyArrays :
}}
姓名为xx006的作者的book的tag数组拆分为多个文档
db.books.aggregate([
{$match:{"author.name":"xx006"}},
{$unwind:"$tag"}
])
每个作者的book的tag合集
db.books.aggregate([
{$unwind:"$tag"},
{$group:{_id:"$author.name",types :{$addToset:"$tag"}}}])
案例
示例数据
db.books.insert([
{"title":"book-51","type":"technology","favCount": 11,"tag":[],"author" : {"name": "fox","age": 28}
},{ "title":"book-52","type":"technology","favCount": 15,"author" : {"name":"fox","age": 28}
},{ "title":"book-53","type":"technology","tag":["nosql","document"],"favCount":20,"author": {"name":"fox","age":28}
}]) 测试
# 使用includeArrayIndex选项来输出数组元素的数组索引
db.books.aggregate([
{$match:{"author.name":"fox"}},
{$unwind:{path:"$tag", includeArrayIndex: "arrayIndex"}}
])
# 使用preserveNullAndEmptyArrays选项在输出中包含缺少size字段,null或空数组的文档db.books.aggregate([
{$match:{"author.name":"fox"}},
{$unwind: {path:"$tag",preserveNullAndEmptyArrays : true}}
])
$limit
限制传递到管道中下一阶段的文档数
db.books.aggregate([
{$limit : 5 }])
此操作仅返回管道传递给它的前5个文档。 $limit对其传递的文档内容没有影响。
注意:当$sort在管道中的$limt之前立即出现时,$sort操作只会在过程中维持前n个结果,其中n是指定的限制,而MongoDB只需要将n个项存储在内存中。
$skip
跳过进入stage的指定数量的文档,并将其余文档传递到管道中的下一个阶段
db.books.aggregate([
{$skip : 5 }])
此操作将跳过管道传递给它的前5个文档。 $skip对沿着管道传递的文档的内容没有影响。
$sort
对所有输入文档进行排序,并按排序顺序将它们返回到管道。
语法:
{ $sort: {
: , : ... }}
要对字段进行排序,请将排序顺序设置为1或-1,以分别指定升序或降序排序,如下例所示:
db.books.aggregate([
{$sort : {favCount:-1,title:1}}
])
$lookup
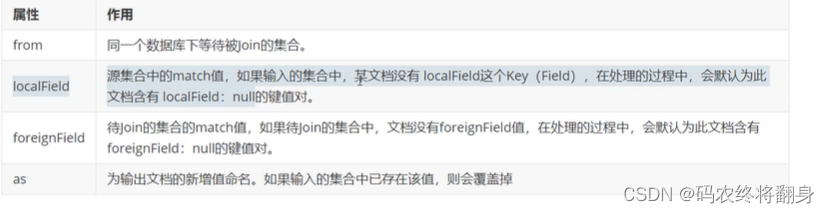
Mongodb 3.2版本新增,主要用来实现多表关联查询,相当关系型数据库中多表关联查询。每个输入待处理的文档,经过$lookup 阶段的处理,输出的新文档中会包含一个新生成的数组(可根据需要命名新key)。数组列存放的数据是来自被join集合的适配文档,如果没有,集合为空(即 为[])
语法:
db.collection.aggregate([{
$lookup:{from: "
", localField:"
", foreignField: "
", as:"
})