08_线程池
08_线程池
- 前言
- Callable接口
- ThreadPoolExecutor
- **为什么用线程池**
- **线程池的好处**
- 架构说明
- 创建线程池
- 底层实现
- 线程池的重要参数
- 拒绝策略
- 线程池底层工作原理
- 问题二: 线程池使用过吗?谈谈在生产上如何设置的参数?
- 线程池的拒绝策略你谈谈?
- 工作中单一的/固定数的/可变数的三种创建线程池的方法你用哪个?
线程池(Java中有哪些方法获取多线程)
问题一: 线程池使用过吗? ThreadPoolExucutor 谈谈理解?
前言
获取多线程的方法,我们都知道有三种,还有一种是实现Callable接口
- 实现Runnable接口
- 实现Callable接口
- 实例化Thread类
- 使用线程池获取
Callable接口
到目前为止我们非常熟悉Runable接口和Thread类创建线程的方式,但是Callable这个接口还是第一次使用
Callable接口,是一种让线程执行完成后,能够返回结果的
在说到Callable接口的时候,我们不得不提到Runnable接口
/*** 实现Runnable接口*/
class MyThread implements Runnable {@Overridepublic void run() {}
我们知道,实现Runnable接口的时候,需要重写run方法,也就是线程在启动的时候,会自动调用的方法
同理,我们实现Callable接口,也需要实现call方法,但是这个时候我们还需要有返回值,这个Callable接口的应用场景一般就在于批处理业务,比如转账的时候,需要给一会返回结果的状态码回来,代表本次操作成功还是失败
/*** Callable有返回值* 批量处理的时候,需要带返回值的接口(例如支付失败的时候,需要返回错误状态)**/
class MyThread2 implements Callable {@Overridepublic Integer call() throws Exception {System.out.println("come in Callable");return 1024;}
}
最后我们需要做的就是通过Thread线程, 将MyThread2实现Callable接口的类包装起来
这里需要用到的是FutureTask类,他实现了Runnable接口,并且还需要传递一个实现Callable接口的类作为构造函数
// FutureTask:实现了Runnable接口,构造函数又需要传入 Callable接口
// 这里通过了FutureTask接触了Callable接口
FutureTask futureTask = new FutureTask<>(new MyThread2());
然后在用Thread进行实例化,传入实现Runnabnle接口的FutureTask的类
Thread t1 = new Thread(futureTask, "aaa");
t1.start();
最后通过 futureTask.get() 获取到返回值
// 输出FutureTask的返回值
System.out.println("result FutureTask " + futureTask.get());
这就相当于原来我们的方式是main方法一条龙之心,后面在引入Callable后,对于执行比较久的线程,可以单独新开一个线程进行执行,最后在进行汇总输出
最后需要注意的是 要求获得Callable线程的计算结果,如果没有计算完成就要去强求,会导致阻塞,直到计算完成
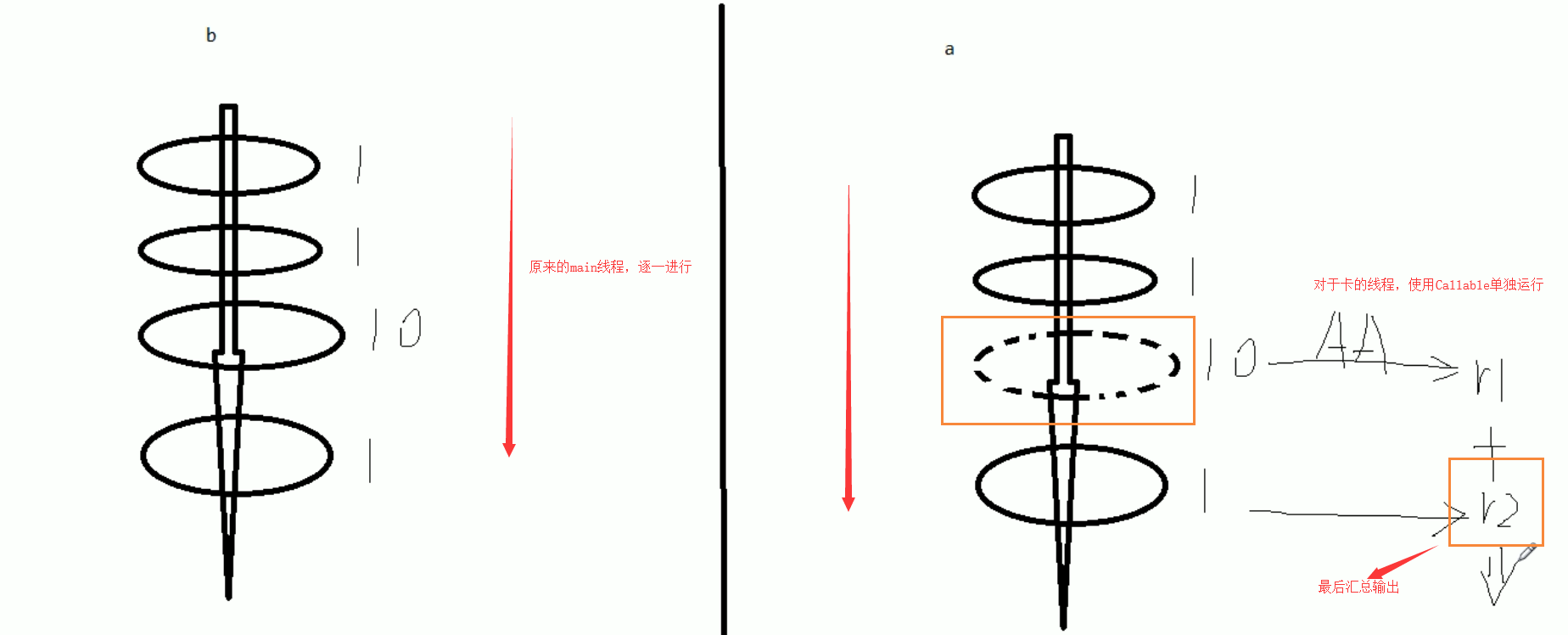
也就是说 futureTask.get() 需要放在最后执行,这样不会导致主线程阻塞
也可以使用下面算法,使用类似于自旋锁的方式来进行判断是否运行完毕
// 判断futureTask是否计算完成
while(!futureTask.isDone()) {}
注意
多个线程执行 一个FutureTask的时候,只会计算一次
FutureTask futureTask = new FutureTask<>(new MyThread2());// 开启两个线程计算futureTask
new Thread(futureTask, "AAA").start();
new Thread(futureTask, "BBB").start();
如果我们要两个线程同时计算任务的话,那么需要这样写,需要定义两个futureTask
FutureTask futureTask = new FutureTask<>(new MyThread2());
FutureTask futureTask2 = new FutureTask<>(new MyThread2());// 开启两个线程计算futureTask
new Thread(futureTask, "AAA").start();new Thread(futureTask2, "BBB").start();
代码:
public class CallableDemo1 {public static void main(String[] args) throws ExecutionException, InterruptedException {FutureTask futureTask = new FutureTask(new Callable() {@Overridepublic Object call() throws Exception {String aa="ddddd";System.out.println("come in call........");System.out.println(Thread.currentThread().getName());try {TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {e.printStackTrace();}return aa;}});new Thread(futureTask,"AA").start();System.out.println("main 线程");System.out.println(futureTask.get());System.out.println("------------------");}
}这个我们需要思考一个问题? 为啥Callable需要借助助于FutureTask?
这个地方我们不得不多思考下?思考的对不对后面再议
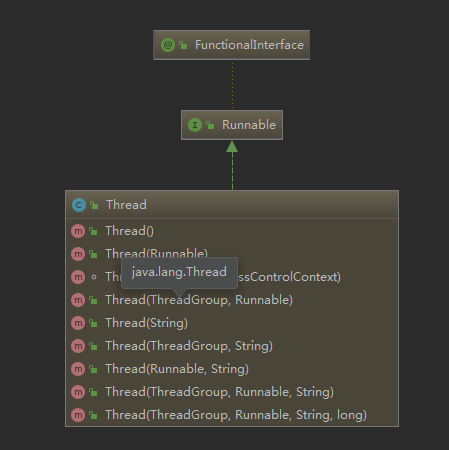
我们可以看出来Thread 构造方法中并没有Callable接口,这种问题就出现了如何使用Callable?
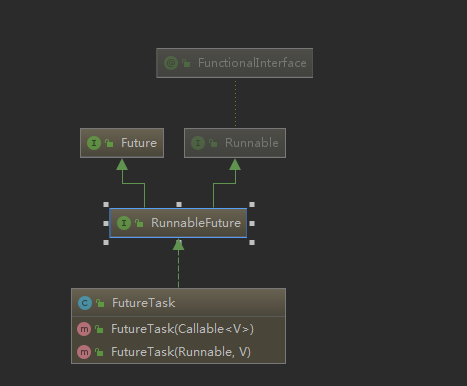
这里是通过FutureTask 构造器进行的注入进来的
ThreadPoolExecutor
为什么用线程池
线程池做的主要工作就是控制运行的线程的数量,处理过程中,将任务放入到队列中,然后线程创建后,启动这些任务,如果线程数量超过了最大数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。
它的主要特点为:线程复用、控制最大并发数、管理线程
线程池中的任务是放入到阻塞队列中的
线程池的好处
多核处理的好处是:省略的上下文的切换开销
原来我们实例化对象的时候,是使用 new关键字进行创建,到了Spring后,我们学了IOC依赖注入,发现Spring帮我们将对象已经加载到了Spring容器中,只需要通过@Autowrite注解,就能够自动注入,从而使用
因此使用多线程有下列的好处
- 降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就立即执行
- 提高线程的可管理性。线程是稀缺资源,如果无线创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
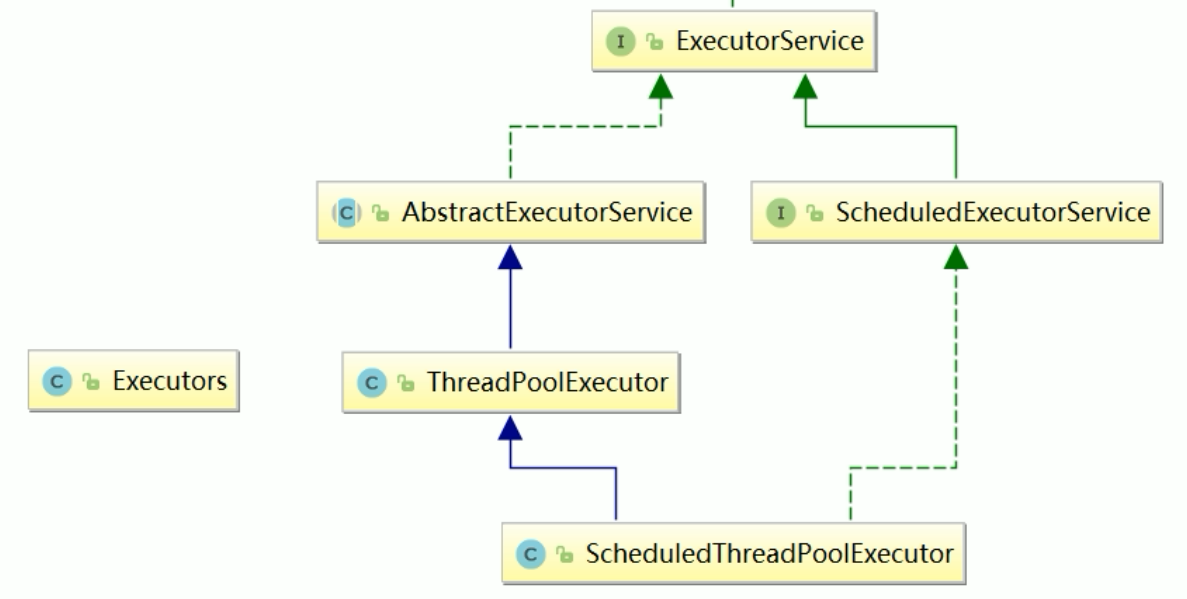
架构说明
Java中线程池是通过Executor框架实现的,该框架中用到了Executor,Executors(代表工具类),ExecutorService,ThreadPoolExecutor这几个类。
架构说明
Java中线程池是通过Executor框架实现的,该框架中用到了Executor,Executors(代表工具类),ExecutorService,ThreadPoolExecutor这几个类。
创建线程池
- Executors.newFixedThreadPool(int i) :创建一个拥有 i 个线程的线程池
1. 执行长期的任务,性能好很多
2. 创建一个定长线程池,可控制线程数最大并发数,超出的线程会在队列中等待 - Executors.newSingleThreadExecutor:创建一个只有1个线程的 单线程池
- 一个任务一个任务执行的场景
- 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行
- Executors.newCacheThreadPool(); 创建一个可扩容的线程池
- 执行很多短期异步的小程序或者负载教轻的服务器
- 创建一个可缓存线程池,如果线程长度超过处理需要,可灵活回收空闲线程,如无可回收,则新建新线程
具体使用,首先我们需要使用Executors工具类,进行创建线程池,这里创建了一个拥有5个线程的线程池
//创建固定大小的一个线程池//ExecutorService executorService = Executors.newFixedThreadPool(5);//创建一个只有一个线程的池//ExecutorService executorService = Executors.newSingleThreadExecutor();//创建带有缓存的线程池ExecutorService executorService = Executors.newCachedThreadPool();
然后我们执行下面的的应用场景
模拟10个用户来办理业务,每个用户就是一个来自外部请求线程
我们需要使用 threadPool.execute执行业务,execute需要传入一个实现了Runnable接口的线程
threadPool.execute(() -> {System.out.println(Thread.currentThread().getName() + "\t 给用户办理业务");
});
然后我们使用完毕后关闭线程池
threadPool.shutdown();
完整代码为:
package com.wfg.thread.threadpool;import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;/*** javaee** @Title: com.wfg.thread.threadpool* @Date: 2020/9/28 6:29* @Author: wfg* @Description:* @Version:*/
public class Dome1 {// Array Arrays(辅助工具类)// Collection Collections(辅助工具类)// Executor Executors(辅助工具类)public static void main(String[] args) {//创建固定大小的一个线程池//ExecutorService executorService = Executors.newFixedThreadPool(5);//创建一个只有一个线程的池//ExecutorService executorService = Executors.newSingleThreadExecutor();//创建带有缓存的线程池ExecutorService executorService = Executors.newCachedThreadPool();try {for (int i = 0; i < 100; i++) { //模拟10个用户final int tmpi=i;executorService.execute(()->{System.out.println(Thread.currentThread().getName() + "正在给客户" + tmpi + "办理业务");});}}catch (Exception e){e.printStackTrace();}finally {executorService.shutdown();}}
}底层实现
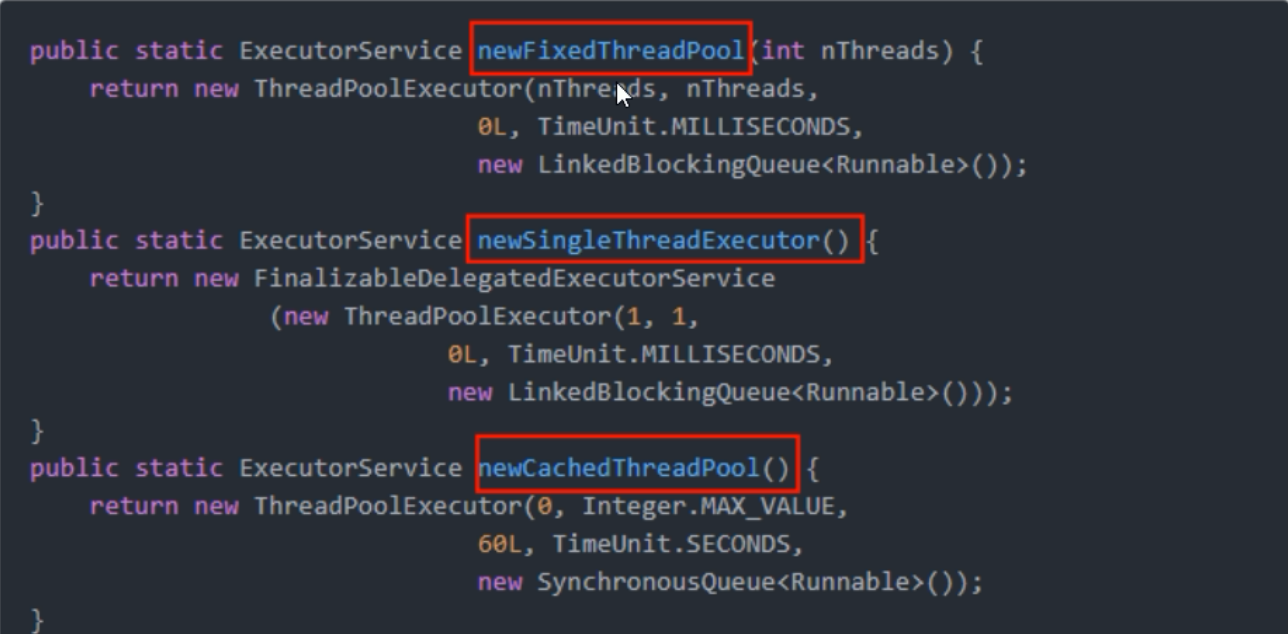
我们通过查看源码,点击了Executors.newSingleThreadExecutor 和 Executors.newFixedThreadPool能够发现底层都是使用了ThreadPoolExecutor

我们可以看到线程池的内部,还使用到了LinkedBlockingQueue 链表阻塞队列
同时在查看Executors.newCacheThreadPool 看到底层用的是 SynchronousBlockingQueue阻塞队列
最后查看一下,完整的三个创建线程的方法
线程池的重要参数
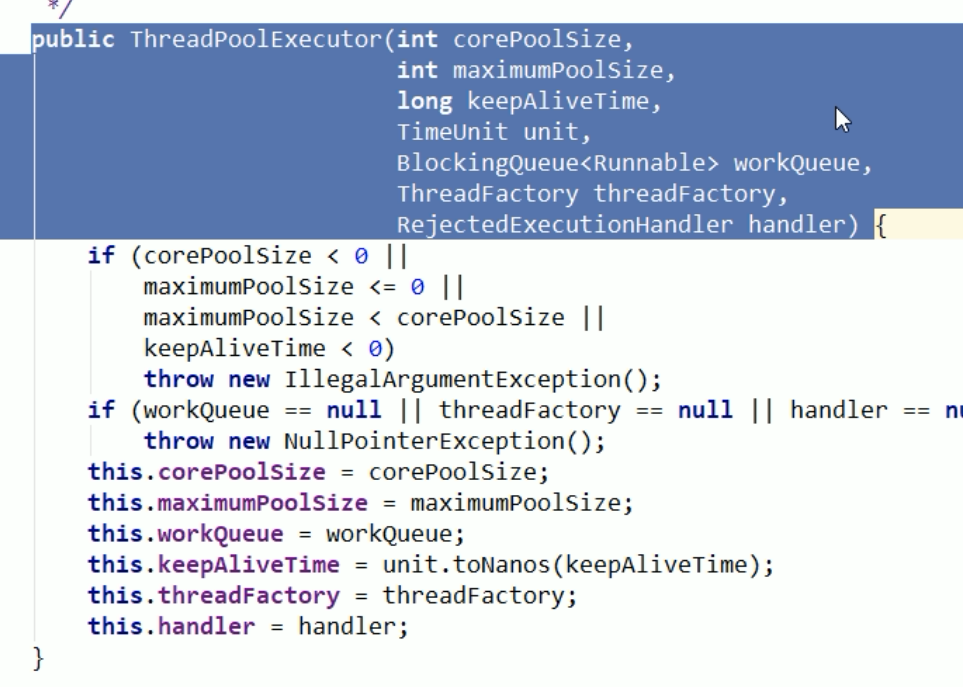
- corePoolSize:核心线程数,线程池中的常驻核心线程数
- 在创建线程池后,当有请求任务来之后,就会安排池中的线程去执行请求任务,近似理解为今日当值线程
- 当线程池中的线程数目达到corePoolSize后,就会把到达的队列放到缓存队列中
- maximumPoolSize:线程池能够容纳同时执行的最大线程数,此值必须大于等于1、
- 相当有扩容后的线程数,这个线程池能容纳的最多线程数
- keepAliveTime:多余的空闲线程存活时间
- 当线程池数量超过corePoolSize时,当空闲时间达到keepAliveTime值时,多余的空闲线程会被销毁,直到只剩下 corePoolSize个线程为止
- 默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用
- unit:keepAliveTime的单位
- workQueue:任务队列,被提交的但未被执行的任务(类似于银行里面的候客区)
- LinkedBlockingQueue:链表阻塞队列
- SynchronousBlockingQueue:同步阻塞队列
- threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程 一般用默认即可
- handler:拒绝策略,表示当队列满了并且工作线程大于线程池的最大线程数(maximumPoolSize3)时,如何来拒绝请求执行的Runnable的策略
当营业窗口和阻塞队列中都满了时候,就需要设置拒绝策略
拒绝策略
以下所有拒绝策略都实现了RejectedExecutionHandler接口
- AbortPolicy:默认,直接抛出RejectedExcutionException异常,阻止系统正常运行
- DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常,如果运行任务丢失,这是一种好方案
- CallerRunsPolicy:该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者
- DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务
个人理解便于记忆: corePoolSize 和 maximumPoolSize 就好比jvm堆内存大小的设置,堆内存大小和堆内存最大,也就是说corePoolSize 是要求线程池中至少这么多线程, 当线程不够用的时候,线程池需要进行创建,但是总不能一直无限的创建,也就是最多maximumPoolSize ,当使用的人少了,这种后来创建的线程又得销毁,不然占用内存浪费,总得有一个规则去销毁:keepAliveTime unit 也就是空闲时间达到我们设置的这么久就需要销毁, workQueue队列是进行保存的,总得有一个缓存,
threadFactory上面已经说了 线程不够用需要创建,这里是使用的工厂模式,
在jvm中堆内存达到最大后还放不下只能报OOM了,线程都达到最大了,队列中也满了怎么搞,拒绝呗,不让再次进入了handler
线程池底层工作原理
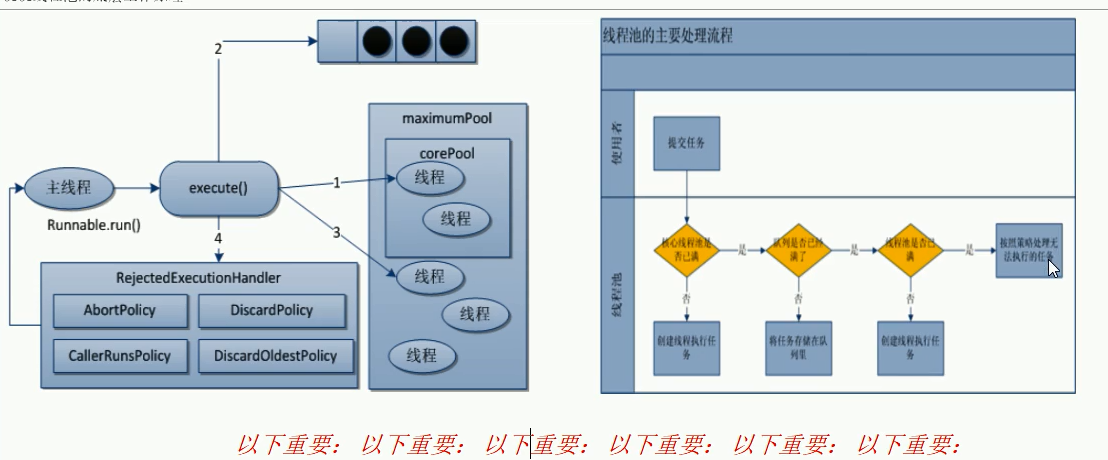
线程池运行架构图
文字说明
-
在创建了线程池后,等待提交过来的任务请求
-
当调用execute()方法添加一个请求任务时,线程池会做出如下判断
- 如果正在运行的线程池数量小于corePoolSize,那么马上创建线程运行这个任务- 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列- 如果这时候队列满了,并且正在运行的线程数量还小于maximumPoolSize,那么**还是创建非核心线程like运行这个任务**;- 如果队列满了并且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行- 当一个线程完成任务时,它会从队列中取下一个任务来执行 -
当一个线程无事可做操作一定的时间(keepAliveTime)时,线程池会判断:
- 如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉- 所以线程池的所有任务完成后,它会最终收缩到corePoolSize的大小
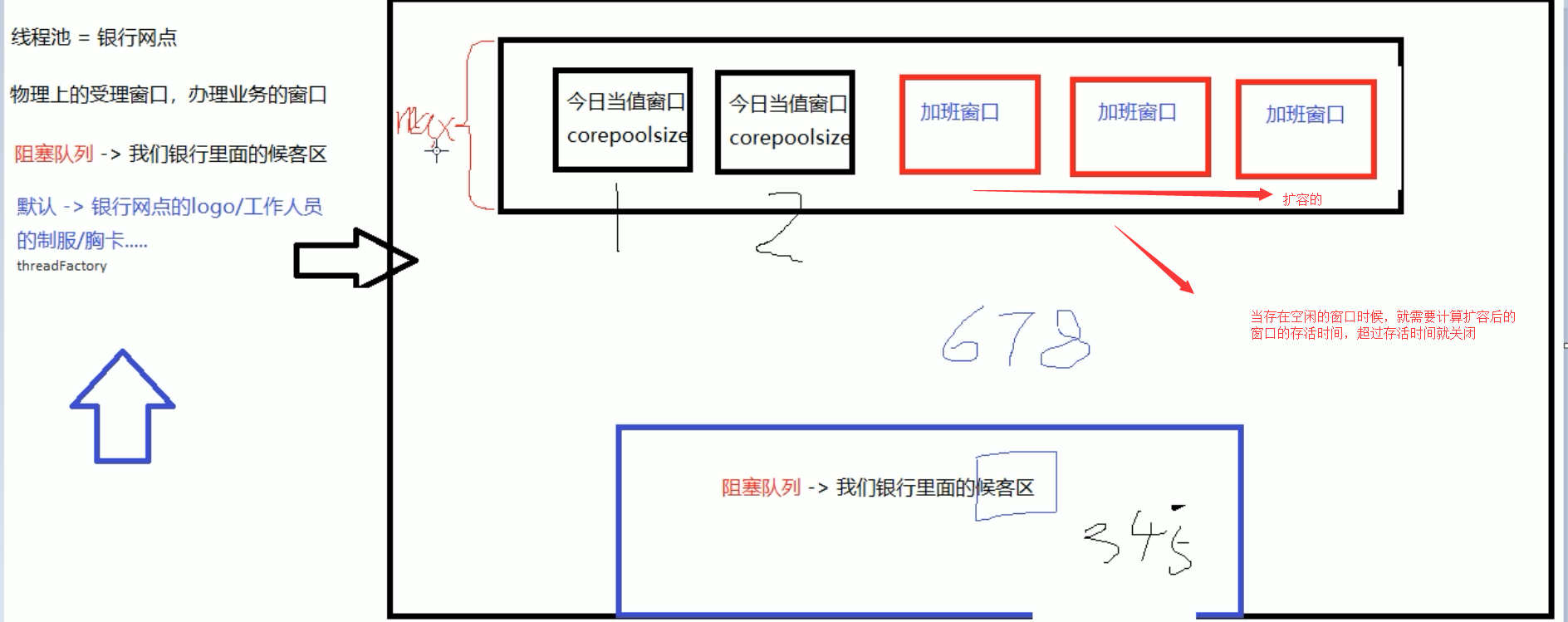
以顾客去银行办理业务为例,谈谈线程池的底层工作原理
- 最开始假设来了两个顾客,因为corePoolSize为2,因此这两个顾客直接能够去窗口办理
- 后面又来了三个顾客,因为corePool已经被顾客占用了,因此只有去候客区,也就是阻塞队列中等待
- 后面的人又陆陆续续来了,候客区可能不够用了,因此需要申请增加处理请求的窗口,这里的窗口指的是线程池中的线程数,以此来解决线程不够用的问题
- 假设受理窗口已经达到最大数,并且请求数还是不断递增,此时候客区和线程池都已经满了,为了防止大量请求冲垮线程池,已经需要开启拒绝策略
- 临时增加的线程会因为超过了最大存活时间,就会销毁,最后从最大数削减到核心数
注意这个地方有一个地方容易忽略的地方: 按照上面的图说吧: 当1 .2 线程正在执行着任务, 线程 3 4 5占满队列的时候才会创建新的线程, 但是创建的新的线程会执行3 4 5还是后面进来的6,经过测试发现是进来的6
public class Demo2 {public static void main(String[] args) {ExecutorService executorService = new ThreadPoolExecutor(2, 5,60L, TimeUnit.SECONDS,new LinkedBlockingQueue<>(3),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());try {for (int i = 1; i <=8; i++) {int tmpi=i;executorService.execute(()->{System.out.println(Thread.currentThread().getName() + "\t 正在办理 " + tmpi + "顾客业务");try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}});}}catch (Exception e){e.printStackTrace();}finally {executorService.shutdown();}}
}
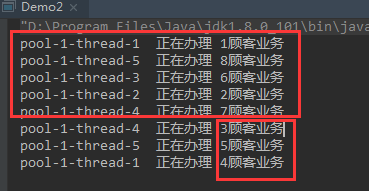
可以看出来 后面创建的线程 3 4 5 是给 6 7 8办理的业务 而3 4 5顾客是等待后面办理的
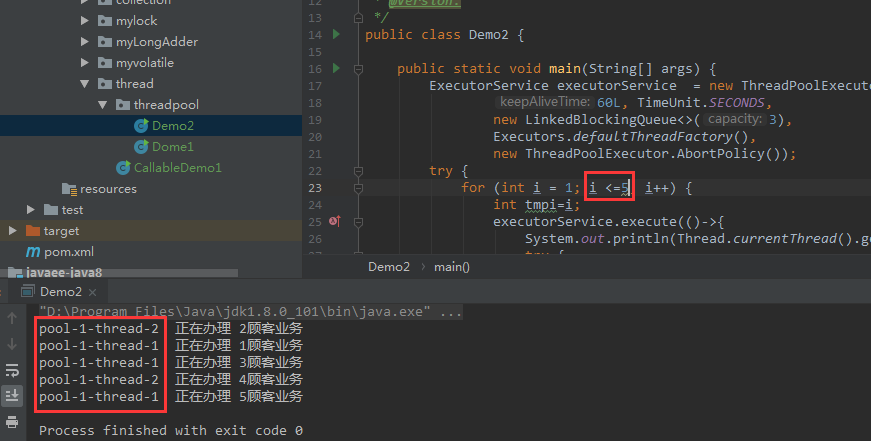
这个地方和使用的哪种队列有关系…后面我们再细细的研究
问题二: 线程池使用过吗?谈谈在生产上如何设置的参数?

线程池的拒绝策略你谈谈?
是什么?
等待队列也已经排满了,再也塞不下新任务了,同时 线程池中的max线程也达到了,无法继续为新任务服务.这个时候我们就需要拒绝策略机制合理的处理这个问题
jdk内置的策略
- AbortPolicy:默认,直接抛出RejectedExcutionException异常,阻止系统正常运行
- DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常,如果运行任务丢失,这是一种好方案
- CallerRunsPolicy:该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者
- DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务
以上内置拒绝策略均实现了RejectedExecutionHandler接口
工作中单一的/固定数的/可变数的三种创建线程池的方法你用哪个?

下面是阿里巴巴中java开发规范中明确规定的,1.不允许在应用中自行显示创建线程; 2,线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,避免资源耗尽的风险