Kaldi的简单介绍和基本使用说明
Kaldi的简单介绍和基本使用说明
- 前言
- 一、ASR简介
- 1.语音识别系统
- 特征提取:
- 声学模型
- 发音词典
- 语言模型
- 语音解码
- 2. ASR项目
- 二、Kaldi简介
- 三、Kaldi项目的结构
- 四、Kaldi的安装
- 1. 安装依赖的几个系统开发库
- 2. 安装依赖的第三方工具库
- 3. 编译Kaldi代码
- 配置Kaldi
- 编译Kaldi
- 五、Kaldi的使用
- 1. 训练模型
- 模型训练前的准备工作
- 训练模型
- 模型训练过程(run.sh)概述
- 2. 搭建语音识别系统
前言
Kaldi是目前最流行的ASR(自动语音识别技术)开源项目之一,已被众多商用的语言识别系统使用。自从2019年Kaldi最主要的开发维护者,被称为Kaldi之父的Daniel Povey加入小米,出任小米集团语音首席科学家后,更加提升了小米的智能语音产品,并且小米也承诺会继续坚持自己纯粹、极致的开源文化,继续不断地加大对Kaldi的投入,持续为Kaldi社区做贡献。
虽然近些年随着神经网络技术的广泛应用,端到端的语音识别技术也随之兴起流行了起来,但也并不意味着Kaldi就要被淘汰了。目前比较流行的端到端开源项目espnet也融合了kaldi的数据处理工具,而且Daniel已经在小米组建团队研发新一代Kaldi(支持端到端),并且已经成功开发,正式发布了。
新一代kaodi项目的相关链接:
1. 核心算法库k2
(https://github.com/k2-fsa/k2)
2. 通用语音数据处理工具包Lhotse
(https://github.com/lhotse-speech/lhotse)
3. 语音识别完整解决方案Icefall
(https://github.com/k2-fsa/icefall)
有兴趣的朋友可以去看看。
Daniel认为,从现有端到端语音识别模型的流行和准确率的逐步提升,到PyTorch、TensorFlow等易用的深度学习工具包的普及,开发新一代Kaldi已势如破竹。但新一代Kaldi的目标不仅仅是赶上或者稍微领先这些语音识别库,而是要根本地改变语音识别的实现方式。
新一代Kaldi已经面世,并且生命力强劲,但下面要介绍的还是传统的基于HMM的语音识别和老的Kaldi项目。
一、ASR简介
ASR(Automatic Speech Recognition)自动语音识别技术,是一种将人的语音转换为文本的技术。ASR是属于自然语言处理(NLP,Natural Language Processing) 的一个应用领域,而输入法(Input Method)、机器翻译(Machine translation)、语音合成(Speech synthesis)等技术也属于NLP的范畴。站在NLP的角度看,这些技术之间有很多相通性,学好一个,对其他的理解和掌握也有帮助。
1.语音识别系统
语音识别,顾名思义,是要把人的声音转化成文本,目标是在给定声音的前提下找到最有可能的文本序列。语音识别系统的结构可以用图1.1表示:
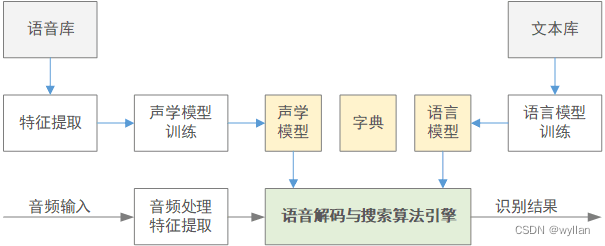
图 1.1 语音识别系统结构图
从图1.1中可以看出,语音识别系统总共有模型训练、语音识别两个过程,包含了特征提取、声学模型、发音词典、语言模型、语音解码五个部分。
- 其中模型训练是语音识别系统的核心工作,单这个过程就包含了图中的全部五个部分(模型训练完成后会用这个模型给语音库中的测试语音解码,然后打分,用误码率的指标来评估模型的识别率)。
- 语音识别的过程和给模型打分的过程差不多,基本可以认为就是把测试语音文件换成了实际输入的音频。
下面来简单说明一下上面提到的五个部分:
特征提取:
不管是语音库中的音频文件还是通过mic输入的音频都是声学信号。声学信号只是根据时间变化的震动波的数字化数据。单从波形看输入的音频根本就没有完全相同的,每个音频都差别很大。但是,根据我们的实践,我们能识别出不同音频的内容,很清楚相同内容的音频之间有相同的特征,所以我们要把这些能分辨的特征从声学参数上体现出来,这就是这里要提到的**声学特征提取**。**声学特征提取**不管是从**时域、频域转换**还是**频谱分析**都牵涉到很多数学、信号处理等学科的专业知识,没有基础的话很难看明白,所以我们可以先了解这里面用到的技术方法名称,感兴趣的可以下去深入学习(包括之后的各部分都是这样)。目前语音识别系统常用的声学特征有:**梅尔频率倒谱系数(MFCC)、感知线性预测(PLP)、Fbank(Filter-bank)** 等。其中MFCC是相对用的比较多的,Fbank是不做DCT(离散余弦变换)的MFCC。一般经过MFCC等的特征提取后还要经过**CMVN**(Cepstral Mean and Variance Normalization,倒谱均值方差归一化)处理,以确保各个特征参数形式一致,特征参数形式不一致就不好比较,在检索匹配特征时会很麻烦。
声学模型
有了声学特征后就要对这些特征进行建模,建模后就相当于一个音频可以用一个函数或公式来描述了,这样想要的结果就通过运算来得到,所以你会发现每一种ASR系统都会用到线性代数库工具。声学模型早期多使用**DTW(Dynamic Time Warping,动态时间规整)**,现在多使用**HMM(Hidden Markov Model,隐马尔可夫模型)**。声学模型训练常使用**GMM(Gaussian mixture model,高斯混合模型)**,随着神经网络算法的兴起**DNN(Deep Neural Networks,深度神经网络)**慢慢成了主流。不过GMM也没有完全废弃,一般的声学模型训练过程还是要先进行**单音素(mono-phone)**的**GMM**训练,接着是**三音素(Triphone)**的**GMM**训练,之后是在此基础之上的**三音素DNN**训练。三音素的GMM训练和DNN训练一般都会迭代好多次,虽然每次迭代后的模型都可以使用,但是一般迭代的次数越多模型越理想。
发音词典
一般是字或词 和 其发言音素的对照表文件,一般形如:
SIL sil sil啊 aa a1啊 aa a2啊 aa a4啊 aa a5啊啊啊 aa a2 aa a2 aa a2啊啊啊 aa a5 aa a5 aa a5阿 aa a1阿 ee e1阿尔 aa a1 ee er3阿根廷 aa a1 g en1 t ing2阿九 aa a1 j iu3... ...... ...坐诊 z uo4 zh en3坐庄 z uo4 zh uang1坐姿 z uo4 z iy1座充 z uo4 ch ong1座驾 z uo4 j ia4
的文本文件。这个文件相对容易制作和获取,只是要特别注意的是,原始发音词典中有一些同音的字词,这个在建立发音词典模型时要特别处理。
语言模型
是从语言学或者说是语法的角度来处理的,不过这里的语言模型并不是通过显式的规定语法规则而是通过统计模型来建模的。比较常用的是用N-gram语言模型。
N-gram模型由于其简单有效,在语音识别中得到了广泛的应用。其目标为计算字符串ω作为一个句子出现的概率P(ω)。解码时会查找匹配出现概率最高的词序组合。
语言模型一般是使用N-gram工具对各种书籍、网页、报刊、新闻等资源的文本信息进行训练的,一般资源越多越好训练出的模型越理想。
语音解码
前面训练出的声学模型、发音词典模型、语言模型基本都可以认为是图的数据结构,解码的本质就是在图的网络中寻找最优路径。
为了加速解码识别效率又引入了WFST(Weighted Finite State Transducer,带权重的有限状态转换器)解码机制,这样可以把动态知识源提取编译好,形成静态网络,在解码时直接调用。从输入HMM状态序列,直接得到词序列及其相关得分。
现在的解码基本上都是基于WFST的,所以前面训练声学模型、发音词典模型、语言模型的时候也都是基于WFST构建的。基于WFST的模型的构建过程称为HCLG过程,也就是用H、C、L、G分别表示上述HMM模型、三音子模型、字典和语言模型的WFST形式。
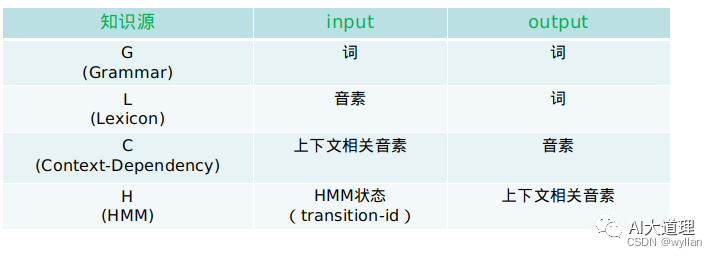
整个过程会生产相应的H.fst、C.fst、L.fst、G.fst:
- G.fst对应语言模型,用来描述词与词之间组合的可能性。
- L.fst对应发音词典,实现单音子到词的转换。
- C.fst描述音素上下文关系的转换,一般是三音子到单音子的转换。
- H.fst表示HMM的转换关系。
最终这4个fst会合并成HCLG.fst的WFST。
一般HCLG网络构建的流程如下:

上面的过程是个静态的解码过程,由于静态网络已经把搜索空间全部展开,它只需要根据节点间的转移权重计算声学概率和累计概率即可,因此解码速度非常快。
用的比较多静态解码的有:
- 基于WFST的Viterbi静态解码
- 基于WFST的Lattice静态解码
其中Viterbi解码识别只保留一条最优路径,若要保存多种候选识别结果,就需要Lattice(因为不能保证viterbi给的最优路径就是真正的对的路径,错误的路径一样可能成为viterbi算法跑出来的最优路径)。
基于静态图HCLG解码的一些问题:
- 静态图HCLG自身占用空间大,难以使用大的语言模型,其在解码运行过程中占用内存也大,难以在移动端直接使用HCLG。
- 静态图HCLG构建过程速度慢,消耗内存高。
就相应的有动态解码:
on-the-fly Composition;
Rescoring(常规Rescoring、on-the-fly Rescoring)。
- on-the-fly Composition动态解码思路是把HCLG分开成HCL和G,称之为HCL/G。构图时分别构建HCL和G,分别构建的HCL和G。因为不是完全展开的图,这两个图的大小远比其展开的静态图HCLG小,这样就节省了空间。另一方面无需再进行HCL和G的Compose这一过程,而这一步恰恰是静态图HCLG构建过程中最为耗时的一步,所以又节省了构图时间。在解码时,分别加载HCL和G,然后根据解码动态的对HCL和G进行按需动态Compose,而无需完全Compose展开。
虽然在节省了构图时间和图的空间,但是动态图HCL/G要在解码时动态的做Compose,也就加大了解码时的计算量,所以解码速度会相对降低。 - Rescoring,其思路是在构建时使用小的LM1构建G1,使用G1构建静态图HCLG1,然后使用小的LM1和大的LM2构建G2(G2中LM的weight为LM2的weight减去LM1的weight)。解码时根据HCLG1和G2的使用方式,又可以做进一步细分:
1)常规Rescoring:利用HCLG1先全部解码,生成lattice或者nbest,然后在G2上做lattice和nbest的Rescoring。
2)on-the-fly Rescoring:使用HCLG1做解码,在解码过程中,每当解码出word时,立即再加上G2中的LM weight,所以称之为on-the-fly Rescoring。Kaldi中的BigLM Decoder即为on-the-fly Rescoring。
实际应用中常常搭建ASR online服务器,供需要语音识别的终端访问,一般服务器资源都比较丰富,所以可以不用担心构图的时间和静态图的大小,而且访问量大,解码效率更为重要,所以基于WFST的Lattice静态解码更为常用。
至于移动终端直接部署ASR的需求,有很多专门的嵌入式离线语音识别方案更为实用。
2. ASR项目
ASR比较流行的项目有早期的HTK、多年来的Kaldi和近年的netesp。
HTK是非常成熟的项目,相关工具、文档等资料都比较完善,而且至今仍在被使用。
Kaldi继承了HTK的很多优点,又做了很多改善,虽然已被广泛使用但是官方资料不够完善。
netesp是端到端语音识别技术中比较流行的一个,发展迅速,广受欢迎。
虽然端到端语音识别是未来语音识别系统非常有前途的发展方向,netesp也很火热,但这里还是选择了Kaldi,Kaldi作为一个优秀的传统语音识别项目,涵盖了语音识别的完整过程,对理解和掌握语音识别有很大帮助,并且其开放的精神,模块化、工具化的特点、降低耦合性,方便用户使用的理念很吸引人。另外Kaldi使用c++开发,不仅主项目开源而且项目使用到的第三方库也都是开源的或者有开源的选项,这样不仅可以方便深入学习Kaodi的实现,而且还可以根据需要来修改扩展,方便为各个平台上移植部署。
至于Kaldi的官方资料不够完善的问题,HTK的丰富资料也都是可以拿来参考(很多技术理论是相同的,而且Kaldi也提供了兼容HTK项目的工具),而且Dan Povey的个人主页 上也有很多资料,众多的Kaldi参与者和使用者也做出了很多贡献。
二、Kaldi简介
关于Kaldi的介绍在官方文档(或者翻译的中文文档)中有更多的描述,这里就不完全照着写了。
-
Kaldi是一个用C + +编写的语音识别工具包,在Apache License v2.0(最自由的开源协议)下授权使用。Kaldi旨在供语音识别研究人员使用(而非普通用户)。
-
Kaldi的目标和HTK类似,它提供了现代和灵活的代码,使用C++实现,容易修改和扩展。
-
Kaldi使用OpenFST作为WFST工具,直接把OpenFST的源码作为一个库编译了进来。(而不是脚本的方式集成)。
-
Kaldi提供了广泛的线性代数支持,包括封装了标准BLAS和LAPACK库的矩阵库,默认使用Intel的MKL(Math Kernel Library),也支持openblas等开源库。
-
Kaldi依赖的如SPHERE音频文件转换工具(sph2pipe)、scoring工具(sctk)、N-gram语言模型工具(srilm或irstlm)等工具和库也都是直接使用源码来构建。
-
尽量避免把简单问题复杂化
Kaldi提供的算法会尽量的简单通用,提功能的每个工具只完成特定的功能。 -
各个模块尽量松耦合。这就意味着一个头文件需要include的头文件尽可能少。比如矩阵库,它只依赖于下面的子目录而完全不依赖其它部分,因此它可以独立于Kaldi的其它部分被使用(比如把它当成一个普通的和Kaldi完全没有关系的矩阵库使用)。
-
完整的recipe
Kaldi对于很多常见语音数据集(主要是LDC的数据,当然也有一些其它开源数据集)的模型训练都提供完整的recipe,从而可以完整的复现整个过程。 -
Kaldi只维护最新的版本,所以用户应该定期更新到最新的master分支。
三、Kaldi项目的结构
Kaldi的项目可以在https://github.com/kaldi-asr/kaldi.git下载
或者使用命令
git clone https://github.com/kaldi-asr/kaldi.git kaldi --origin upstream
cd kaldi
git pull
通过git pull命令可以更新项目并修复一些bug。
进入项目的根目录,可以看到下面这些文件和目录
ls
cmake/
docker/
egs/
tools/
misc/
scripts/
src/
windows/
COPYING
CMakeLists.txt
INSTALL
README.md
| 一级目录 | 内容 |
|---|---|
| egs | Kaldi的实例,包含了语音识别,语种识别,声纹识别,关键字识别等。 |
| misc | 包含了一些 pdf,以及相关 docker,htk 等资源。 |
| scripts | 只用来存放 Rnnlm,以及相应的运行脚本。 |
| src | 存放 Kaldi 的源代码,包括GMM,Ivector,Nnet等一系列的传统语音识别算法。 |
| tools | 主要存放 Kaldi 依赖库的安装脚本。 |
| windows | 在 Windows 平台运行所必须的脚本以及相关的执行程序。 |
其中,tools、src、egs这三个目录是比较重要的。
- tools目录下面全部都是Kaldi依赖的包。其中主要有:
| 工具 | 内容 |
|---|---|
| OpenFst | 加权有限状态转换器(FST)的库。 |
| IRSTLM | 一种统计语言建模工具包。可以将任何Arpa格式的语言模型转换为FST。 |
| SRILM | 一种统计语言建模工具包。它是比IRSTLM更好,更完整的语言建模工具包。 |
| sph2pipe | 一款处理SPHERE_formatted数字音频文件的软件,它可以将LDC的sph格式的文件转换成其它格式。 |
| sclite | 这是NIST SCTK打分工具的一部分,用于生成符合NIST评测规范的统计文件。 |
| CUB | 是NVIDIA官方提供的CUDA核函数开发库,是目前Kaldi编译的必选工具 |
| ATLAS | 线性代数库。 |
| CLAPACK | 线性代数库。这仅在没有ATLAS且使用CLAPACK进行编译的系统上有用。 |
| OpenBLAS | 这是ATLAS或CLAPACK的替代方案。 |
| MKL | Intel 的 数学核心库,作为默认的线性代数库 |
-
egs目录下的很多实例就是前面提到的语音数据集的完整的recipe,下面列出几个常用的实例,更详细的可以访问这里和官网
实例 描述 Aishell 此目录为中文语音识别和声纹识别相关例子。 Aishell2 此目录主要为中文语音识别例子,但是针对 Aishell 在脚本方面更加规整。 rm 英语语音识别例子,包含了如何进行迁移学习。 thchs30 普通话语音识别例子。 wsj wsj 英文语音识别例子。 -
src 目录为 Kaldi 的源码目录,在这个目录中,有两类文件夹,一类是算法原目录,一类为算法组合生成bin(可执行程序)目录,下面随便列举几个,想深入学习的可以访问这里和官网。
| 目录 | 功能 |
|---|---|
| base | 基础目录,主要包括与 Kaldi 项目相关的基础宏定义、类型定义等。 |
| bin | 基础 bin 目录,主要是包括基础的执行程序。例如,查看 tree 信息、矩阵拷贝等基础操作。 |
| cudamatrix | 矩阵计算相关 GPU 计算 |
| matrix | 矩阵计算相关 CPU 计算 |
| hmm | 隐马尔可夫算法的代码 |
| feat | 特征提取算法目录 |
| featbin | 特征提取可执行目录 |
| gmm | GMM 算法 |
| gmmbin | GMM 算法可执行文件目录 |
| ivector | ivector 算法基础目录 |
| ivectorbin | ivector 算法的可执行目录,以及基于能量的 vad 执行目录。 |
| lat | 网格生成基础算法目录 |
| latbin | 网格生成算法的可执行文件目录 |
| nnet3 | nnet3 相关基础算法实现目录 |
| nnet3bin | nnet3 相关实现算法的可执行文件目录 |
| online | online1 相关解码算法的实现目录 |
| onlinebin | online1 相关解码器算法的可执行目录 |
| online2 | online2 相关解码器算法的实现目录 |
| online2bin | online2 相关解码器算法的可执行目录 |
四、Kaldi的安装
Kaldi不是一个终端用户软件,没有安装包。安装Kaldi指的是编译Kaldi代码,以及准备一些必要的工具和运行环境。
由于Kaldi的示例都是使用shell脚本的,并且其I/O大量依赖管道,因此最佳的运行环境是UNIX类系统。这里以Ubuntu为例。
1. 安装依赖的几个系统开发库
在编译Kaldi之前,先要检查和安装Kaldi依赖的几个系统开发库,这些库有很多(g++、LLVM、Clang、zlib、python、gawk、perl、wget、git、libtool等),可以暂时不用知道有哪些,只需进入Kaldi下面的tools目录执行extras/check_dependencies.sh脚本来检查依赖的库是否已经安装,没有的话会给出提示,之后根据提示把缺少的库安装下就好了。
cd kaldi/tools/
extras/check_dependencies.sh
特别要注意的是Kaldi的线性代数库默认是IntelMKL,没有安装的话会给出提醒,如果想使用其他其他线性代数库的话(比如ATLAS或OpenBLAS)可以忽略。
2. 安装依赖的第三方工具库
进入kaldi/tools目录,执行make
cd kaldi/tools/
make
这样如果成功的话ATLAS headers、OpenFst、SCTK 、sph2pipe、CUB都会被自动下载编译安装,如果github能访问的话,基本都能顺利安装,如果不能访问可以把从这个地方下载好的压缩包放到tools目录下,然后对照更改下tools/Makefile中相应库的版本号,之后再执行make就可以了。
tools/Makefile中相应库的版本号位置如下:
# SHELL += -xCXX ?= g++
CC ?= gcc # used for sph2pipe
# CXX = clang++ # Uncomment these lines...
# CC = clang # ...to build with Clang.WGET ?= wgetOPENFST_VERSION ?= 1.7.2
CUB_VERSION ?= 1.8.0
# No '?=', since there exists only one version of sph2pipe.
SPH2PIPE_VERSION = 2.5
# SCTK official repo does not have version tags. Here's the mapping:
# 2.4.9 = 659bc36; 2.4.10 = d914e1b; 2.4.11 = 20159b5.
SCTK_GITHASH = 2.4.12
安装语音模型工具
cd kaldi/tools/
extras/install_irstlm.sh
extras/install_srilm.sh
extras/install_kaldi_lm.sh
IRSTLM / SRILM / Kaldi_lm 这是三个不同的语言模型工具,不同的示例使用不同的工具。
其中安装SRILM有两点需要注意
-
第一、SRILM是商业软件,不是免费的,需要到SRILM网站上注册、接受许可协议才能下载,并且要重命名为srilm.tgz放到tools目录下。
-
第二、SRILM的安装依赖lbfgs库,这个库的安装方式为
cd kaldi/tools/ extras/install_liblbfgs.shSRILM等源码包我已经下载好放在了这里需要的话可以直接下载使用。
安装线性代数库
OpenBLAS / MKL / ATLAS / CLAPACK 任选一个就行,
-
其中MKL是默认使用的 非常庞大且不开源,另外安装完Intel MKL后,不管是安装还是使用kaldi都要先在当前终端下以source方式执行MKL安装目录下的setvars.sh。
-
ATLAS与OpenBLAS是开源的,性能基本接近MKL,其中OpenBLAS会比ATLAS运行效率更高些。
-
CLAPACK 是 在LAPACK的基础上,增加了c的调用方式,而LAPACK底层是调用的BLAS代码库。BLAS是一个早期很经典的一个库,他定义了后续线性代数库的API接口规范,但是太过老旧,没有针对架构进行优化,效率比较慢。
OpenBLAS和MKL的安装方式如下:cd kaldi/tools/ extras/install_openblas.sh extras/install_mkl.sh安装CUDA
执行神经网络时要使用GPU进行运算,Kaldi的GPU计算部分使用了NVIDIA的CUDA框架。
除了CUDA框架的工具CUDA Toolkit外还需要用到CUDA的dnn工具cuDNN,这些工具都可在NVIDIA官网上下载CUDA Toolkit、cuDNN。
Kaldi通常支持最新的版本,在安装过程中需要root权限,每一步都使用默认设置,按照提示一步步执行就好。
安装好后查看CUDA的安装位置
ls -l /usr/local/cuda
lrwxrwxrwx 1 root root 22 11月 8 11:59 /usr/local/cuda -> /etc/alternatives/cuda/
ls -l /etc/alternatives/cuda
lrwxrwxrwx 1 root root 20 11月 8 11:59 /etc/alternatives/cuda -> /usr/local/cuda-11.7/
查看CUDA 编译工具nvcc的版本
/usr/local/cuda/bin/nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Jun__8_16:49:14_PDT_2022
Cuda compilation tools, release 11.7, V11.7.99
Build cuda_11.7.r11.7/compiler.31442593_0
需要注意的是CUDA的工具不会自动添加到环境变量中,使用时需要自己添加。
将 /usr/local/cuda/bin 加入 PATH 环境变量
将 /usr/local/cuda/lib64 加入 LD_LIBRARY_PATH 环境变量
3. 编译Kaldi代码
Kaldi的源代码使用gnu的autotools构建系统,可以根据配置自动生成相应平台的编译文件,
下面x86平台的PC机为例。
配置Kaldi
autotools构建系统是使用configure命令来配置的,关键配置如下:
cd kaldi/src./configure --help--static # 静态编译,会得到静态库,生成文件比较大,便于移植,默认不使用--shared # 动态编译,会得到动态库和比较小的可执行文件,不便移植,默认不使用--double-precision # 双浮点精度,默认不使用# CUDA相关设置--use-cuda # 使用CUDA,默认使用,如果只用CPU运算,则不启用--cudatk-dir=DIR # CUDA安装位置,默认是/usr/local/cuda--cuda-arch=FLAGS # CUDA架构的相关参数,不配置就使用默认参数,详情可以查看:# https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html# 特别要注意的是要指定当前显卡的架构的版本代号,否则默认是用最新架构,这样可能会有问题,# 其参数的格式为 --cuda-arch=-arch=sm_xy ,xy是两个数字分别代表第几代和子版本# OpenFst 相关设置--static-fst # 使用静态OpenFst库,默认不使用--fst-root=DIR # OpenFst 安装位置,默认是../tools/openfst/# 线性代数库相关设置--mathlib=LIB # 指定数学库,可选MKL(默认)、OPENBLAS、ATLAS、CLAPACK。--static-math # 指定静态数学库,默认不使用--atlas-root=DIR # ATLAS 安装位置,默认是../tools/ATLAS/--openblas-root=DIR # OpenBLAS 安装位置,默认是../tools/openblas/--clapack-root=DIR # CLAPACK 安装位置--mkl-root=DIR # MKL 安装位置--mkl-libdir=DIR # MKL库安装位置
使用默认数学库MKL、动态编译、不使用 gpu 的配置命令
./configure --shared --use-cuda=no
使用 gpu 则配置去掉 --use-cuda=no 并 加上
--use-cuda --cudatk-dir=/usr/local/cuda/ --cuda-arch=-arch=sm_62
使用数学库使用OpenBLAS 则加上
--mathlib=OPENBLAS --openblas-root=../tools/openblas/
推荐的完整配置命令为
./configure --shared --use-cuda --cudatk-dir=/usr/local/cuda/ --cuda-arch=-arch=sm_62 --mathlib=OPENBLAS --openblas-root=../tools/openblas/
编译Kaldi
配置成功后终端上就会给出Kaldi的编译命令
make depend -j 8
make -j 8
编译的时间比较长,请耐心等待,
上面的命令执行成功后Kaldi就算安装成功了。
五、Kaldi的使用
Kaldi安装成功后,接下来就可以使用egs下面的示例或者参照这些示例来训练模型,搭建语音识别系统了。
使用自己的语音库,来训练模型需要编写整理不少文件和脚本,还是比较复杂的,这里就不深入说明,只以希尔贝壳的开源语音库Aishell为例来说明怎么使用。
Aishell的recipe已经在kaldi/egs/目录下存在了,基本就是最新的,可以直接使用。
1. 训练模型
进入Aishell的recipe目录
cd kaldi/egs/aishell/
ls
s5/
v1/
README.txt
查看README.txt文件
cat README.txt
... ...
s5: a speech recognition recipe
v1: a speaker recognition recipe
... ...
我们知道
s5是语音识别的recipe,
v1是说话人识别的recipe,
这里使用s5就行。
ls s5
drwx------ 10 4096 9月 23 10:01 ./
drwx------ 4 4096 9月 22 21:36 ../
drwx------ 2 4096 8月 18 17:00 conf/
drwx------ 4 4096 8月 18 17:00 local/
lrwxrwxrwx 1 62 8月 18 17:00 steps -> ../wsj/s5/steps/
lrwxrwxrwx 1 62 8月 18 17:00 utils -> ../wsj/s5/utils/
-rw-rw-r-- 1 1018 8月 18 17:00 cmd.sh
-rw-r--r-- 1 421 8月 18 17:00 path.sh
-rw-rw-r-- 1 1514 8月 18 17:00 RESULTS
-rw-r--r-- 1 6025 8月 18 17:00 run.sh
s5下的目录中
- steps 和 utils 是指向egs/wsj示例下的相应目录,这两个文件夹下包含了好多通用脚本,被所有的示例共用。
- steps 中的是各个训练阶段的子脚本,如特征提取、GMM训练、dnn训练、解码等。
- utils 中的脚本是更细小的工具,用于协助处理, 如任务管理、文件夹整理、临时文件删除、数据复制和验证等。
- local 目录下的是处理当前示例数据的脚本、识别测试的脚本、以及出GMM训练之外的其他训练步骤的脚本。这些脚本调用了大量steps和utils目录下的脚本。
- conf 目录下保存了一些如特征提取和识别解码的配置文件。
- path.sh 定义了训练脚本中所使用的环境变量的位置,包括kaldi编译输出的位置、kaldi/tools下各个工具的位置、steps和utils脚本的位置等。
- cmd.sh 定义了训练任务的提交方式。相关命令使用run.pl就是单机执行,使用queue.pl就是任务管理服务器集群的任务提交方式。常用的集群系统有SGE、PBS、SLURM,默认使用SGE,但个人建议使用SLURM是开源免费的,其维护积极,资料全,而且很多大型商用服务器都在使用,表现出色。当然只有一台电脑就直接使用run.pl就行了。
- run.sh 是顶层运行脚本,集成了从资源下载、数据准备、特征提取到模型训练和测试的全部脚本,并给出了获取统计结果的方法。直接运行run.sh就可以得到训练测试好的模型。
- RESULTS 是结果列表文件,给出了run.sh中每一步训练的模型在测试集上的效果。
模型训练前的准备工作
-
首先要准备一台有NVIDIA高性能独立显卡的电脑,否则 dnn 的 nnet3 或 chain 训练无法完成。
-
Aishell的语音库在数据准备的脚本中会自动下载,不过语音库数据有十几个GB,可以事先在Aishell官网,或者在openslr(本人测试发现openslr中的资源的下载链接中,欧洲的最好)下载好data_aishell.tgz 和resource_aishell.tgz 。放在同一个目录下,然后修改run.sh中data路径为此目录,即可。
#data=/export/a05/xna/data data=Aishell的语音库所在目录 data_url=www.openslr.org/resources/33 -
修改cmd.sh ,因为我们是单机运行,所以需要将相关的queue.pl都改成run.pl(run.pl后面的–mem参数没有意义)。
#export train_cmd="queue.pl --mem 2G" #export decode_cmd="queue.pl --mem 4G" #export mkgraph_cmd="queue.pl --mem 8G" export train_cmd="run.pl" export decode_cmd="run.pl" export mkgraph_cmd="run.pl" -
修改path.sh,保证KALDI_ROOT的路径是当前kaldi项目的根目录(src和tools的上级目录),其他的不需要改。
export KALDI_ROOT=`pwd`/../../.. #修改这里的值,如果是kaldi/egs/下的示例则不需要修改 [ -f $KALDI_ROOT/tools/env.sh ] && . $KALDI_ROOT/tools/env.sh export PATH=$PWD/utils/:$KALDI_ROOT/tools/openfst/bin:$PWD:$PATH [ ! -f $KALDI_ROOT/tools/config/common_path.sh ] && echo >&2 "The standard file $KALDI_ROOT/tools/config/common_path.sh is not present -> Exit!" && exit 1 . $KALDI_ROOT/tools/config/common_path.sh export LC_ALL=C export PYTHONUNBUFFERED=1 -
确认 GPU 的运算环境
-
检查cuda toolkit环境
nvcc --version 如果出现 Command 'nvcc' not found, but can be installed with: apt install nvidia-cuda-toolkit 说明cuda-toolkit没有安装或这没有配置环境变量
-
如果cuda-toolkit已经安装需要执行
export PATH=$PATH:/usr/local/cuda/bin
配置成功后可以看到
nvcc --version
nvcc: NVIDIA ® Cuda compiler driver
Copyright © 2005-2022 NVIDIA Corporation
Built on Wed_Jun__8_16:49:14_PDT_2022
Cuda compilation tools, release 11.7, V11.7.99
Build cuda_11.7.r11.7/compiler.31442593_0
2. 修改GPU模式为独占式运行模式(dnn训练时非常消耗显卡存储资源,如果同时执行多个训练任务,显卡资源会很快枯竭。)```shellsudo nvidia-smi -c 3Set compute mode to EXCLUSIVE_PROCESS for GPU 00000000:01:00.0.
All done.
-
修改local/chain/run_tdnn.sh和local/nnet3/run_tdnn.sh,把
--use-gpu=true 设置成–use-gpu=wait,没有则不修改。 (理由同上)if [ $stage -le 8 ]; then if [[ $(hostname -f) == *.clsp.jhu.edu ]] && [ ! -d $dir/egs/storage ]; then utils/create_split_dir.pl \/export/b0{5,6,7,8}/$USER/kaldi-data/egs/aishell-$(date +'%m_%d_%H_%M')/s5/$dir/egs/storage $dir/egs/storage fisteps/nnet3/train_dnn.py --stage=$train_stage \ --cmd="$decode_cmd" \ --feat.online-ivector-dir exp/nnet3/ivectors_${train_set} \ --feat.cmvn-opts="--norm-means=false --norm-vars=false" \ --trainer.num-epochs $num_epochs \ --trainer.optimization.num-jobs-initial $num_jobs_initial \ --trainer.optimization.num-jobs-final $num_jobs_final \ --trainer.optimization.initial-effective-lrate $initial_effective_lrate \ --trainer.optimization.final-effective-lrate $final_effective_lrate \ --egs.dir "$common_egs_dir" \ --cleanup.remove-egs $remove_egs \ --cleanup.preserve-model-interval 500 \ --use-gpu wait \ ## 修改这里 把 true 改为 wait --feat-dir=data/${train_set}_hires \ --ali-dir $ali_dir \ --lang data/lang \ --reporting.email="$reporting_email" \ --dir=$dir || exit 1; fi至此准备工作就基本完成了。
训练模型
准备工作完成后给run.sh加上可执行权限,然后直接执行静待完成即可。(训练时间会非常长,可能要好多天)
chmod a+x run.sh ./run.sh
模型训练过程(run.sh)概述
#!/usr/bin/env bash# Copyright 2017 Beijing Shell Shell Tech. Co. Ltd. (Authors: Hui Bu)
# 2017 Jiayu Du
# 2017 Xingyu Na
# 2017 Bengu Wu
# 2017 Hao Zheng
# Apache 2.0# This is a shell script, but it's recommended that you run the commands one by
# one by copying and pasting into the shell.
# Caution: some of the graph creation steps use quite a bit of memory, so you
# should run this on a machine that has sufficient memory.data=/export/a05/xna/data
data_url=www.openslr.org/resources/33. ./cmd.sh############# 下载语音库数据 #############
local/download_and_untar.sh $data $data_url data_aishell || exit 1;
local/download_and_untar.sh $data $data_url resource_aishell || exit 1;############# 预处理发音词典 #############
# Lexicon Preparation,
local/aishell_prepare_dict.sh $data/resource_aishell || exit 1;############# 声学训练的数据准备 ############
# Data Preparation,
local/aishell_data_prep.sh $data/data_aishell/wav $data/data_aishell/transcript || exit 1;############# 准备并训练语言模型 ############
# Phone Sets, questions, L compilation
utils/prepare_lang.sh --position-dependent-phones false data/local/dict \"" data/local/lang data/lang || exit 1;# LM training
local/aishell_train_lms.sh || exit 1;# G compilation, check LG composition
utils/format_lm.sh data/lang data/local/lm/3gram-mincount/lm_unpruned.gz \data/local/dict/lexicon.txt data/lang_test || exit 1;############# 提取语音库中的音频特征 ###########
# Now make MFCC plus pitch features.
# mfccdir should be some place with a largish disk where you
# want to store MFCC features.
mfccdir=mfcc
for x in train dev test; dosteps/make_mfcc_pitch.sh --cmd "$train_cmd" --nj 10 data/$x exp/make_mfcc/$x $mfccdir || exit 1;steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x $mfccdir || exit 1;utils/fix_data_dir.sh data/$x || exit 1;
done############### 训练单音素 GMM-HMM模型 ############
# Train a monophone model on delta features.
steps/train_mono.sh --cmd "$train_cmd" --nj 10 \data/train data/lang exp/mono || exit 1;############### 解码,测试 训练出的单音素 GMM-HMM模型,并评估打分 #############
############ 解码前要构建状态图 ###########
# Decode with the monophone model.
utils/mkgraph.sh data/lang_test exp/mono exp/mono/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \exp/mono/graph data/dev exp/mono/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \exp/mono/graph data/test exp/mono/decode_test############### 在单音素 GMM-HMM模型 的基础上 训练三音素 GMM-HMM模型 ###############
########### 开始训练前要先将上一次训练出的模型进行gmm对齐 ###########
# Get alignments from monophone system.
steps/align_si.sh --cmd "$train_cmd" --nj 10 \data/train data/lang exp/mono exp/mono_ali || exit 1;# Train the first triphone pass model tri1 on delta + delta-delta features.
steps/train_deltas.sh --cmd "$train_cmd" \2500 20000 data/train data/lang exp/mono_ali exp/tri1 || exit 1;############### 解码,测试 训练出的三音素 GMM-HMM模型,并评估打分 #############
############ 同样解码前要构建状态图 ###########
# decode tri1
utils/mkgraph.sh data/lang_test exp/tri1 exp/tri1/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \exp/tri1/graph data/dev exp/tri1/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \exp/tri1/graph data/test exp/tri1/decode_test
... ...
... ...
# align tri4a with fMLLR
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \data/train data/lang exp/tri4a exp/tri4a_ali# Train tri5a, which is LDA+MLLT+SAT
# Building a larger SAT system. You can see the num-leaves is 3500 and tot-gauss is 100000steps/train_sat.sh --cmd "$train_cmd" \3500 100000 data/train data/lang exp/tri4a_ali exp/tri5a || exit 1;# decode tri5a
utils/mkgraph.sh data/lang_test exp/tri5a exp/tri5a/graph || exit 1;
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \exp/tri5a/graph data/dev exp/tri5a/decode_dev || exit 1;
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \exp/tri5a/graph data/test exp/tri5a/decode_test || exit 1;############### 到此为止 三音素 GMM-HMM模型 训练 共进行了 5 次迭代 ############################## 在最后一个三音素 GMM-HMM模型 tri5a 的基础上 训练三音素 NNET3-HMM模型 ###############
########### 同样 在开始nnet3训练前要先将tri5a的模型进行对齐 ###########
# align tri5a with fMLLR
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \data/train data/lang exp/tri5a exp/tri5a_ali || exit 1;# nnet3
local/nnet3/run_tdnn.sh############### 在三音素 NNET3-HMM模型的基础上 训练三音素 NNET3-CHAIN-HMM模型 ###############
# chain
local/chain/run_tdnn.sh############### 打印每个训练的模型的测试打分结果(即WER,word error rate)###############
# getting results (see RESULTS file)
for x in exp/*/decode_test; do [ -d $x ] && grep WER $x/cer_* | utils/best_wer.sh; done 2>/dev/null
for x in exp/*/*/decode_test; do [ -d $x ] && grep WER $x/cer_* | utils/best_wer.sh; done 2>/dev/nullexit 0;
上面的训练过程中前面的语音库准备、发音词典处理,声学训练的数据准备、语言模型数据的准备是个很繁杂细致的工作,是最需要使用者做的工作,虽然后面的模型训练、测试等工作也很多,但是因为有很多实现好的工具和脚本,最难的部分不需要自己来做,反而轻松很多。
2. 搭建语音识别系统
语音识别就是将人说话的音频数据 提取特征 然后使用已训练好的模型来进行解码,得到说话的文本内容。
所以,语音识别系统就包括了音频数据的获取、音频特征提取、语音识别模型的导入和配置、使用模型解码音频。
下面使用上面训练出的 nnet3-chain模型 和 kaldi的online2-tcp-nnet3-decode-faster工具来演示:
-
准备解码所需的配置文件
steps/online/nnet3/prepare_online_decoding.sh \--add-pitch true \ #aishell训练时提取的特征加入了pitch(音高)特征,所以这里也要加上data/lang_chain \ #存储了chain模型解码网络图中的G.fst和L.fst文件以及词汇表words.txt文件exp/nnet3/extractor \ #有关特征提取器的一些文件exp/chain/tdnn_1a_sp \ #chain模型的存放路径nnet_online #生成的解码配置文件存放路径解码配置文件生成后要检查修改nnet_online/conf/mfcc.conf为
--use-energy=false # only non-default option. --sample-frequency=16000 ######下面4行参数和mfcc_hire有关######## --num-mel-bins=40 # similar to Google's setup. --num-ceps=40 # there is no dimensionality reduction. --low-freq=40 # low cutoff frequency for mel bins --high-freq=-200 # high cutoff frequently,relative to Nyquist of 8000 (=3800)因为默认生成的特征类型是MFCC,而aishell训练nnet和chain模型输入的是更高维度的MFCC,叫mfcc_hire(hire是high resolution单词的缩写),所以这个地方要把mfcc_hire的参数加上,否则解码时会报维度不匹配的错误。
-
运行nnet3在线语音识别服务器online2-tcp-nnet3-decode-faster,监听tcp传输的实时音频数据,并返回解码结果
online2-tcp-nnet3-decode-faster --samp-freq=16000 \--frames-per-chunk=20 --extra-left-context-initial=0 \--frame-subsampling-factor=3 \--config=nnet_online/conf/online.conf \ #解码配置文件的主文件--min-active=200 --max-active=7000 --beam=15.0 \--lattice-beam=6.0 --acoustic-scale=1.0 、--port-num=5050 \ # tcp服务监听端口nnet_online/final.mdl \ # chain模型文件exp/chain/tdnn_1a_sp/graph/HCLG.fst \ # chain解码图文件data/lang_chain/words.txt # chain词汇表文件 -
传输音频数据给online2-tcp-nnet3-decode-faster获取解码结果
#发送一个音频文件audio.wav给语音识别服务器 sox audio.wav -t raw -c 1 -b 16 -r 8k -e signed-integer - | nc -N localhost 5050 #通过MIC录音并事实传输给语音识别服务器 rec -r 8k -e signed-integer -c 1 -b 16 -t raw -q - | nc -N localhost 5050
通过上面3步,一个简单的语音识别系统就算完成了。
实际应用中有很多人用gstreamer来搭建kaldi在线语音识别系统。
其中还用到了kaldi-gstreamer-server、 gst-kaldi-nnet2-online gstreamer插件
感兴趣的朋友可以自己研究下。
参考资料
《Kaldi语音识别实践》—— 陈果果,都家宇,那兴宇,张俊博著
《基于声调信息的拉萨方言声学建模方法研究》—— 李建
Kaldi官方文档
Daniel Povey 的个人网站
OpenSLR—Open Speech and Language Resources
Kaldi官方文档的部分中文翻译和整理- 李想
AI大道理的语音识别(ASR)专栏
AI大道理的语音框架(Kaldi)专栏
Kaldi的HCLG构图过程可视化