
翻译:
这是这个问题的简单版本。唯一的区别是𝑛和𝑘上的约束。只有当所有版本的问题都解决了,你才能进行hack。
你有一个字符串𝑠,你可以对它做两种类型的操作:
删除字符串的最后一个字符。
复制字符串:𝑠:=𝑠+𝑠,其中+表示连接。
每个操作可以使用任意次数(可能不使用)。
您的任务是通过对字符串𝑠执行这些操作,找到长度恰好为𝑘的字典编纂学上最小的字符串。
当且仅当下列条件之一满足时,字符串𝑎在字典结构上小于字符串𝑏:
𝑎是𝑏的前缀,但𝑎≠𝑏;
在𝑎和𝑏不同的第一个位置上,字符串𝑎在字母表中出现的字母比𝑏中相应的字母更早。
输入
第一行包含两个整数𝑛,𝑘(1≤𝑛,𝑘≤5000)—原始字符串𝑠的长度和所需字符串的长度。
第二行包含字符串𝑠,由𝑛小写英文字母组成。
输出
打印长度为𝑘的按字典顺序最小的字符串,该字符串可以通过对字符串𝑠进行操作获得。
例子
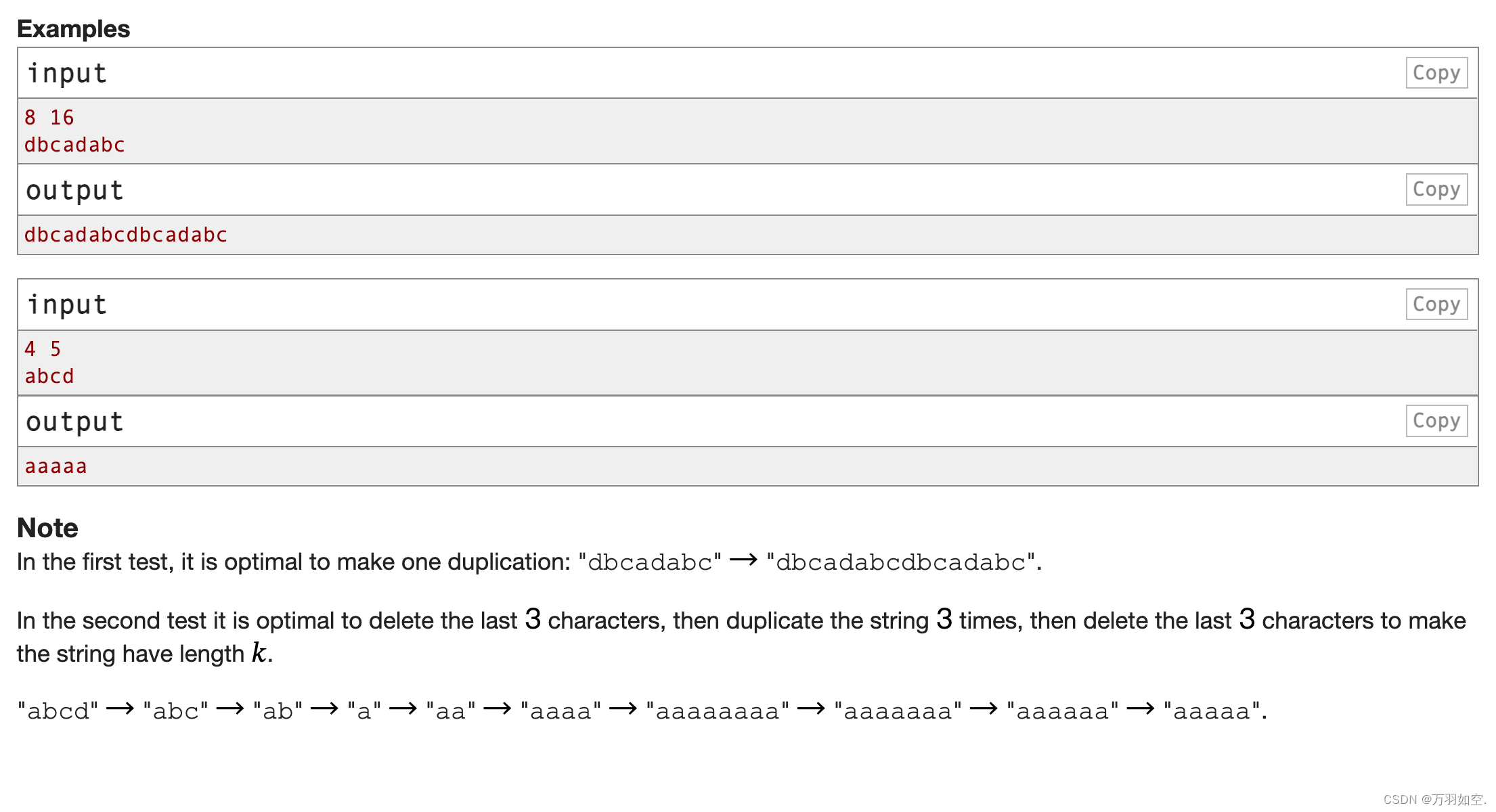
inputCopy
8 16
dbcadabc
outputCopy
dbcadabcdbcadabc
inputCopy
4个5
abcd
outputCopy
五星级
请注意
在第一个测试中,做一个副本是最优的:"dbcadabc"→"dbcadabcdbcadabc"。
在第二个测试中,最好是删除最后3个字符,然后复制字符串3次,然后删除最后3个字符,使字符串的长度为𝑘。
“abcd”→“abc”→“ab”→“a”→“aa”→“aaaa”→“aaaaaaaa”→“aaaaaaa”→“aaaaaa”→“aaaaa”。
思路:
可以删除最后一个,然后复制字符串,然后构成长度为k的,其字典序最小的字符串。所以我们直接从前往后每次比较,如果前边的字符比后面的小则可以替代,如果相同则就是比较下一位,然后来不断更新最小的串。
上边的一份代码是暴力模拟T掉,因为这样模拟,遇到全是小回文串的字符串,每次都会跑完,直接被无情卡掉。
代码:
//#include
//#include
//#include
//#include
//#include
//#include
//#include
//#include
//#include
//#include