spark安装与入门
下载
https://archive.apache.org/dist/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz
Local 模式
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux,解压
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
重命名
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-local
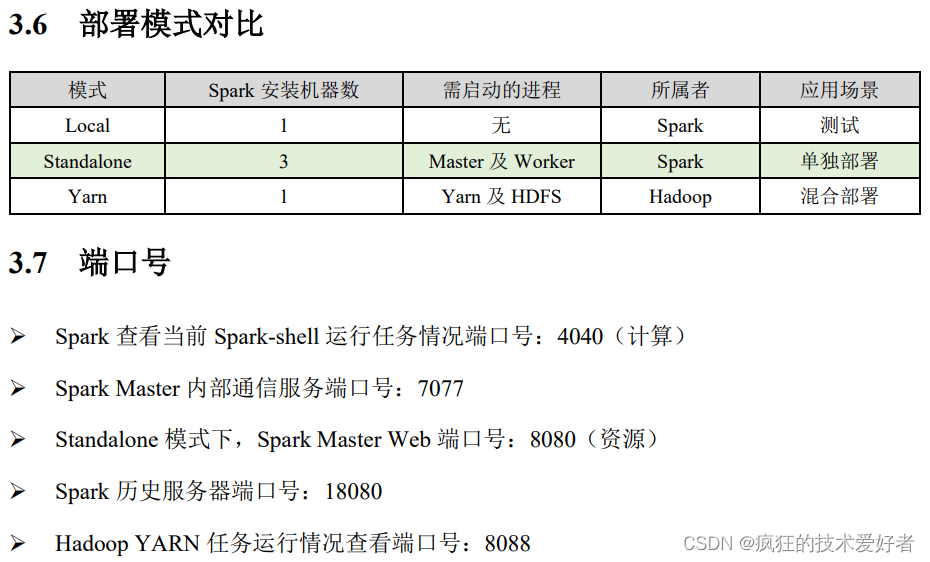
启动 Local 环境(如果启动失败,看看是否解压没完全,可能空间不足,清空/tmp目录)
bin/spark-shell
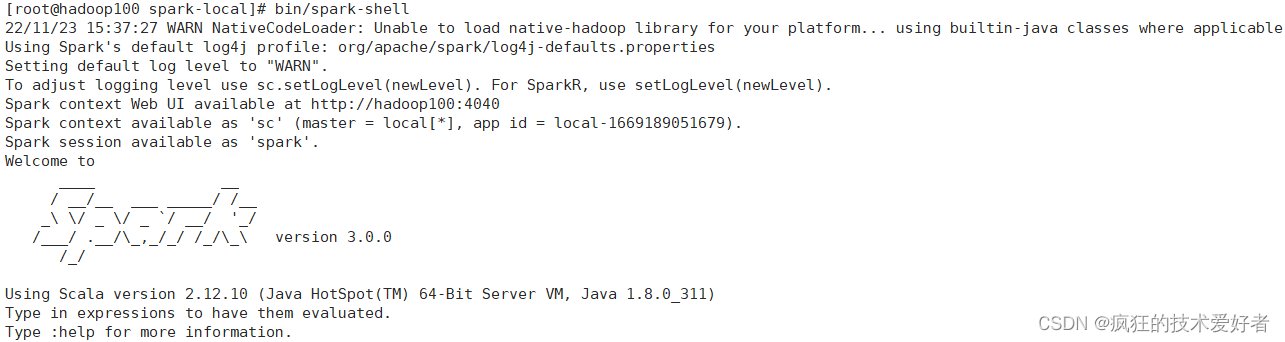
webui监控页面
http://虚拟机地址:4040/
在解压缩文件夹下的 data 目录中,添加 word.txt 文件,内容Hello World Hello Spark
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
结果如下图
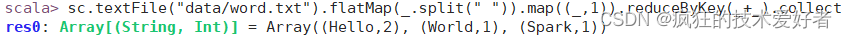
提交应用
bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ./examples/jars/spark-examples_2.12-3.0.0.jar 10
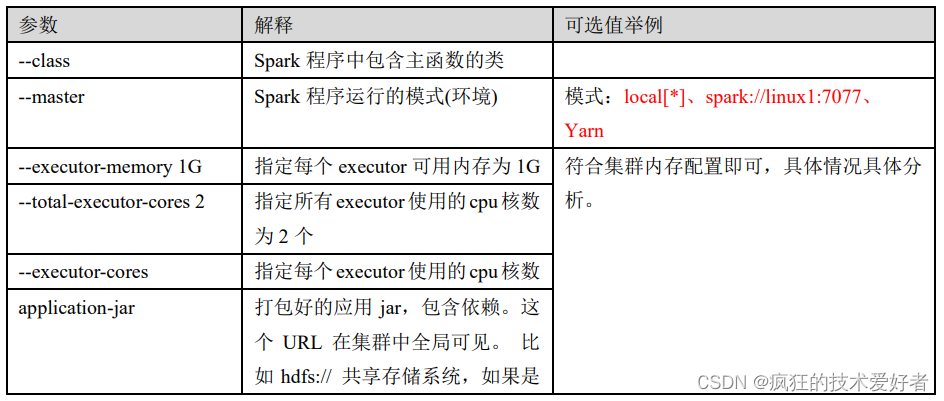
- –class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
- –master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
- spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱们自己打的 jar 包
- 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
结果如下图
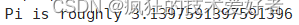
Standalone 模式(经典的 master-slave 模式)
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux,解压
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
重命名
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
修改配置文件
cd conf
复制配置文件
cp slaves.template slaves
修改 slaves 文件,添加 work 节点
hadoop100
hadoop101
hadoop102
复制 spark-env.sh.template 文件名为 spark-env.sh
cp spark-env.sh.template spark-env.sh
查看JAVA_HOME路径
echo $JAVA_HOME
查看主机名称
hostname
修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/usr/java/jdk1.8.0_311-amd64
SPARK_MASTER_HOST=hadoop100
SPARK_MASTER_PORT=7077
分发到其他服务器
/home/xsync /opt/module/spark-standalone
启动
sbin/start-all.sh
jps查看三台服务器进程

查看 Master 资源监控 Web UI 界面: http://hadoop100:8080
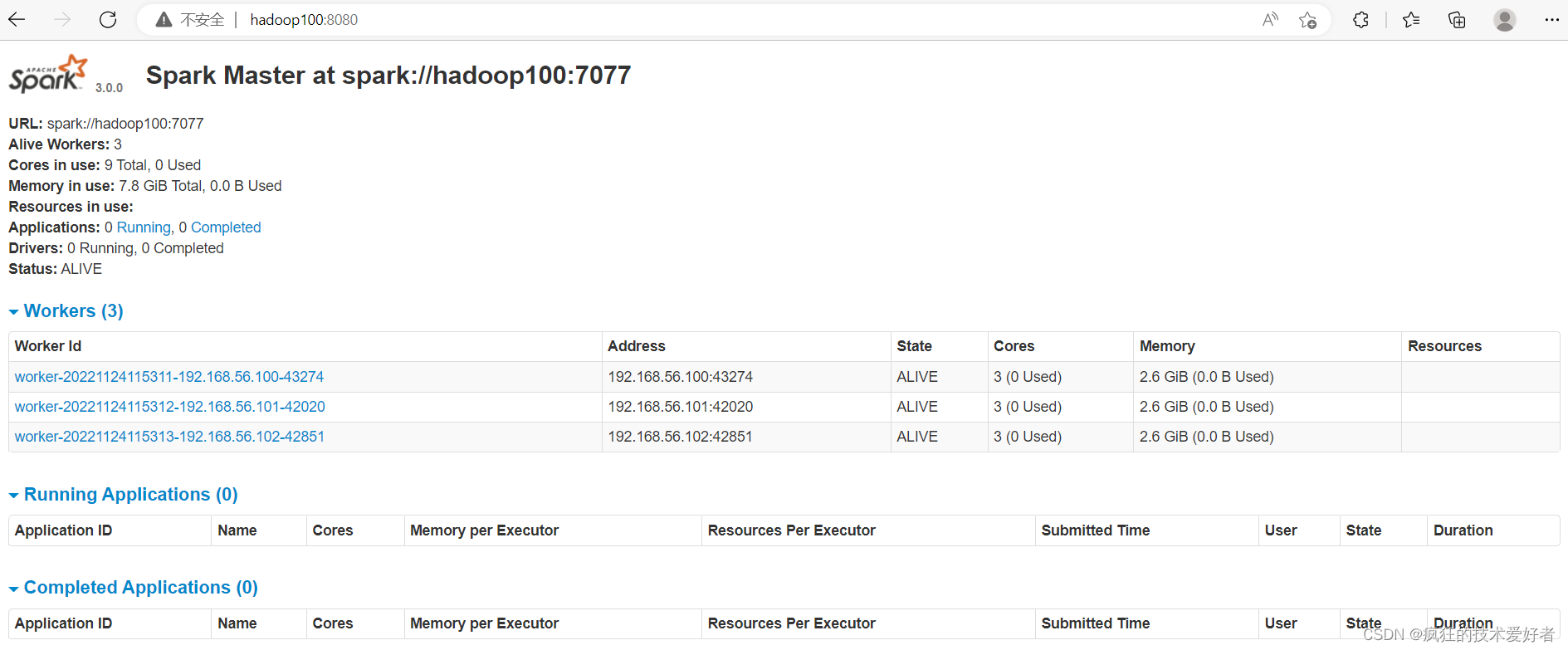
提交应用
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop100:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10
配置历史服务
需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在
/opt/module/hadoop-3.1.3/sbin/start-dfs.sh
hadoop fs -mkdir /directory
查看地址 http://hadoop100:9870/
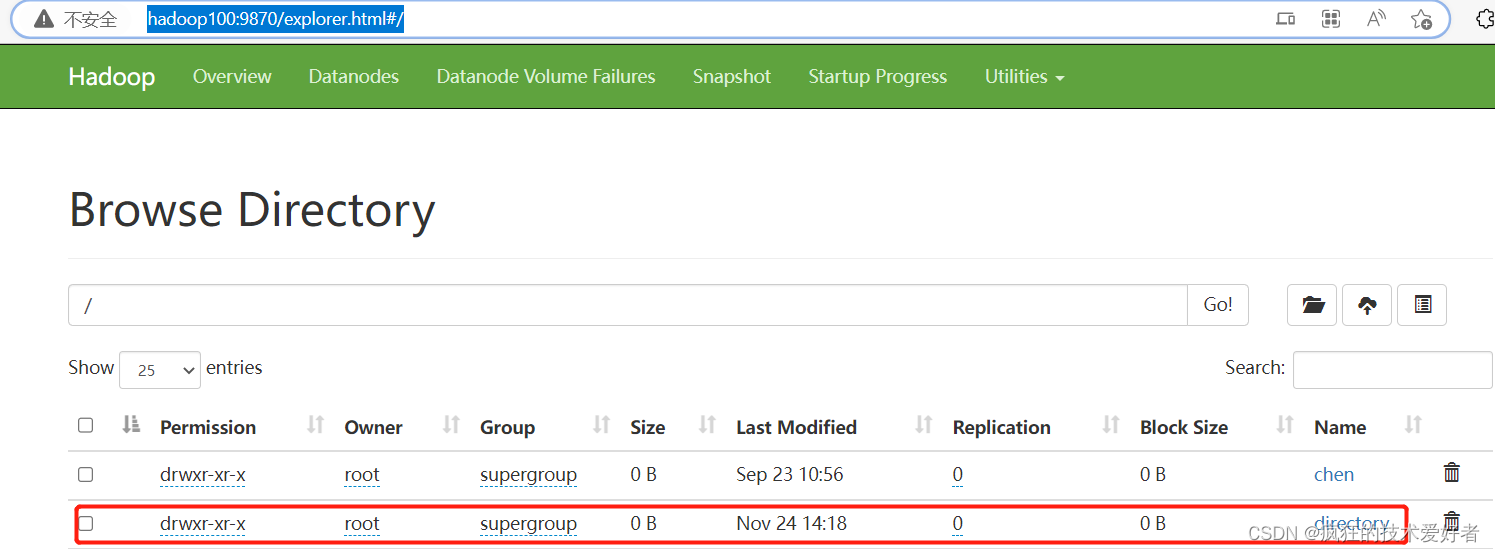
配置日志存储路径
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:8020/directory
添加历史日志服务
vim spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory
-Dspark.history.retainedApplications=30"
分发到其他服务器
/home/xsync /opt/module/spark-standalone
重新启动集群和历史服务
sbin/stop-all.sh
sbin/start-all.sh
sbin/start-history-server.sh
重新执行任务
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop100:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10
配置高可用(HA)

停止集群
sbin/stop-all.sh
启动 Zookeeper
/home/zk.sh start
vim spark-env.sh 文件添加如下配置
注释如下内容:
#SPARK_MASTER_HOST=hadoop100
#SPARK_MASTER_PORT=7077
添加如下内容:
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop100,hadoop101,hadoop102
-Dspark.deploy.zookeeper.dir=/spark"
分发到其他服务器
/home/xsync /opt/module/spark-standalone/conf
启动集群
[root@hadoop100 spark-standalone]# sbin/start-all.sh
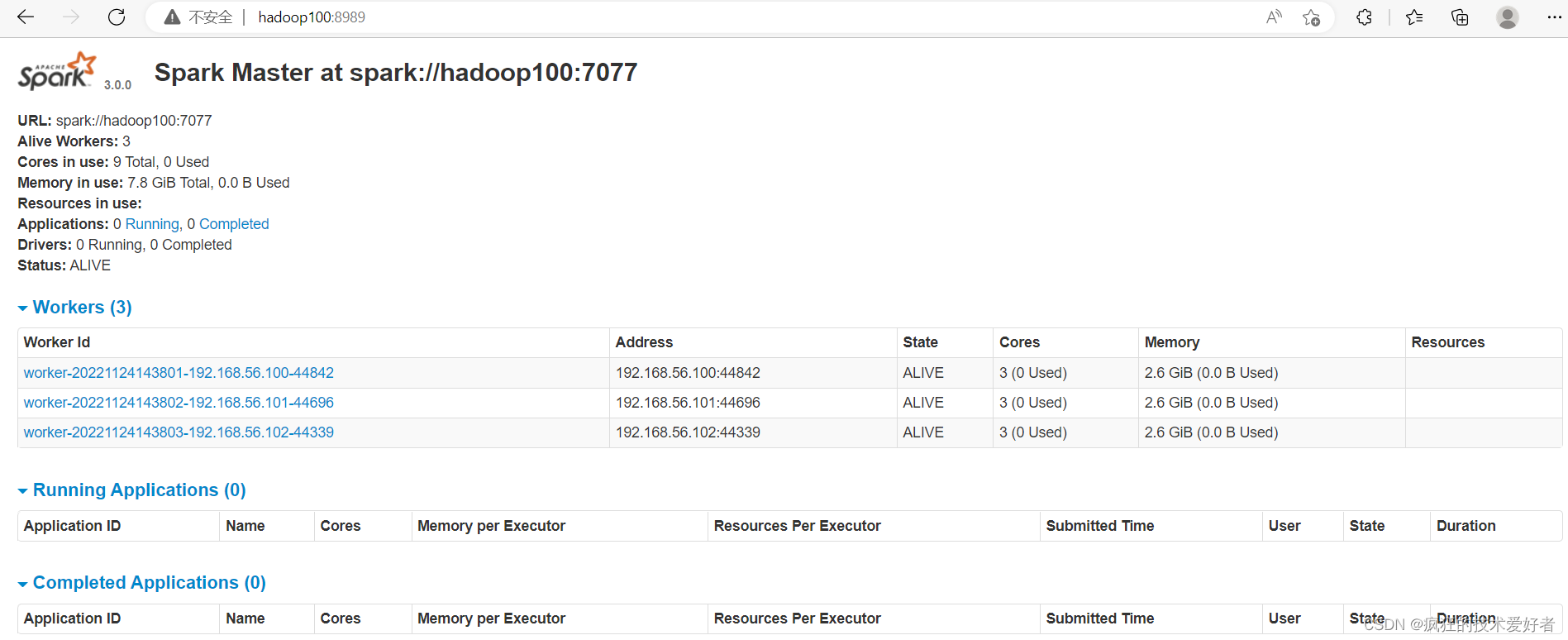
启动 hadoop101 的单独 Master 节点,此时 hadoop101 节点 Master 状态处于备用状态
[root@hadoop101 spark-standalone]# sbin/start-master.sh
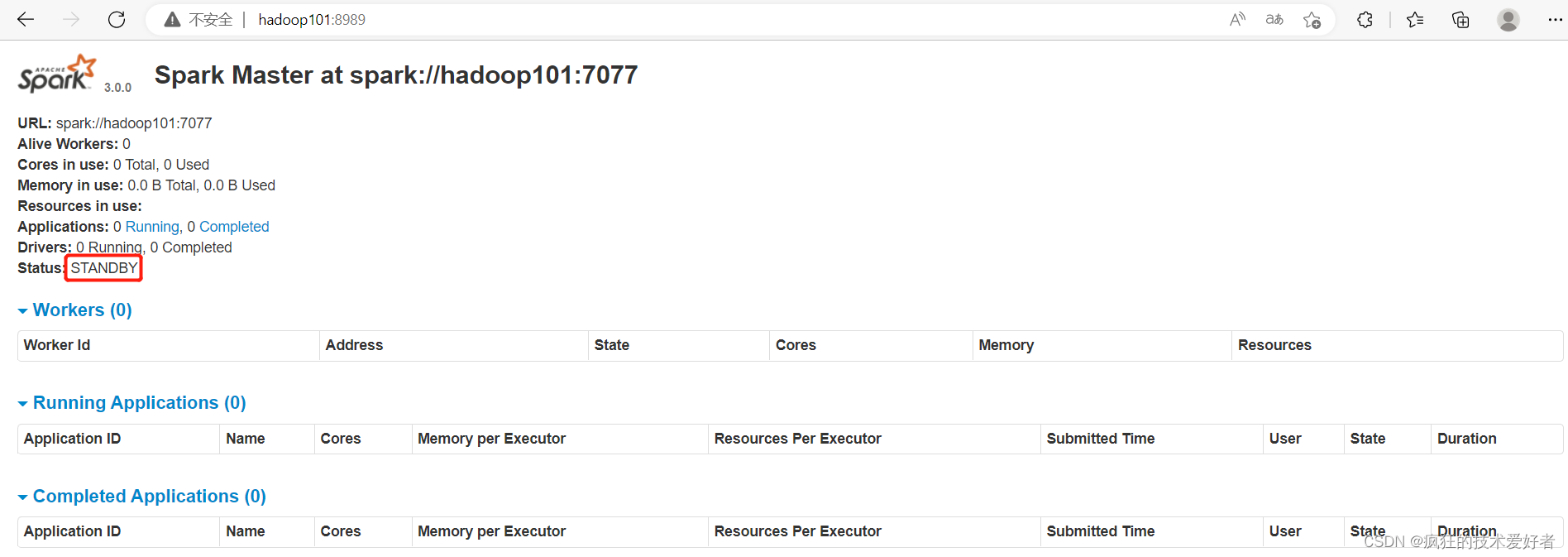
提交任务到高可用集群
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop100:7077,hadoop101:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10
得到Pi值说明成功
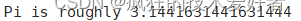
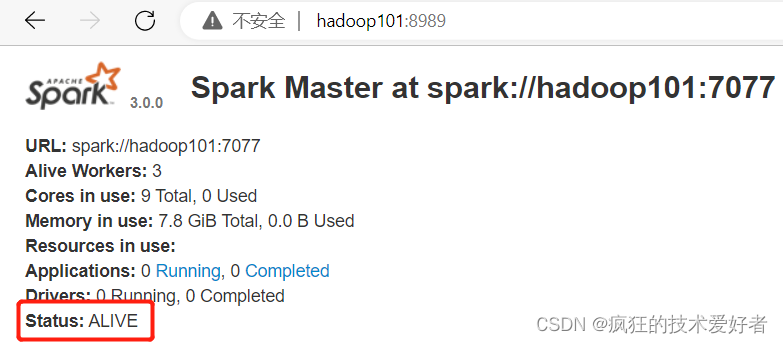
停止 hadoop100 的 Master 资源,监控进程 kill -9 15872

可以看到状态变为 ALIVE
Yarn 模式(生产一般采用此模式)
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux,解压
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
重命名
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn
修改配置文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
yarn.nodemanager.pmem-check-enabled false
yarn.nodemanager.vmem-check-enabled false
复制 spark-env.sh.template 文件名为 spark-env.sh
cp spark-env.sh.template spark-env.sh
修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
export JAVA_HOME=/usr/java/jdk1.8.0_311-amd64
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
hadoop集群启停脚本 https://blog.csdn.net/weixin_44371237/article/details/126040977
提交任务到高可用集群
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.12-3.0.0.jar 10
配置历史服务
配置日志存储路径
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:8020/directory
添加历史日志服务
vim spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory
-Dspark.history.retainedApplications=30"
修改 spark-defaults.conf
spark.yarn.historyServer.address=hadoop100:18080
spark.history.ui.port=18080
hadoop集群启停脚本 https://blog.csdn.net/weixin_44371237/article/details/126040977
HDFS 上的 directory 目录需要提前存在
hadoop fs -mkdir /directory
查看地址 http://hadoop100:9870/
启动历史服务
sbin/start-history-server.sh
提交任务到高可用集群
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.12-3.0.0.jar 10
Windows 模式
将文件 spark-3.0.0-bin-hadoop3.2.tgz 解压缩到无中文无空格的路径中
执行解压缩文件路径下 bin 目录中的 spark-shell.cmd 文件,启动 Spark 本地环境
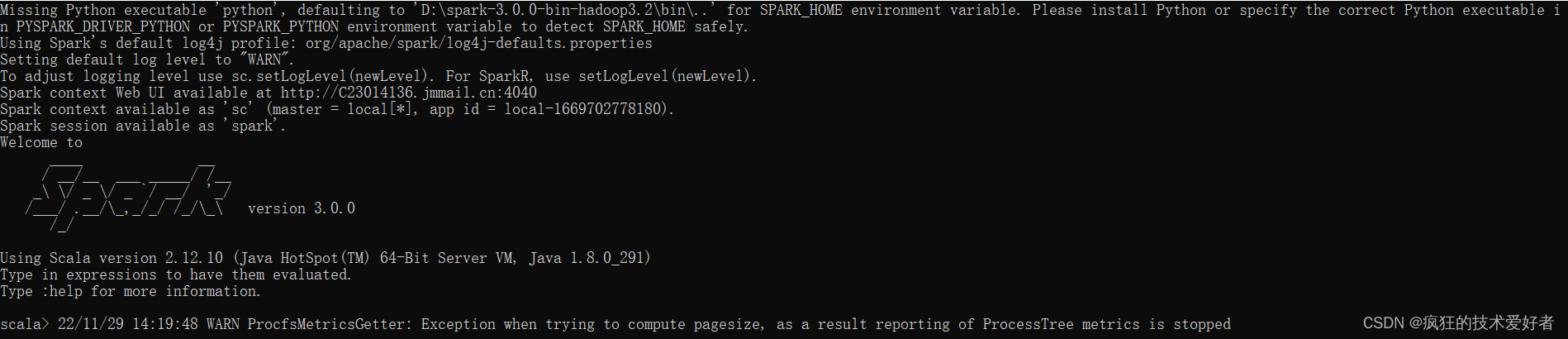
在 bin 目录中创建 input 目录,并添加 word.txt 文件, 在命令行中输入脚本代码
sc.textFile("D:\\spark-3.0.0-bin-hadoop3.2\\bin\\input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
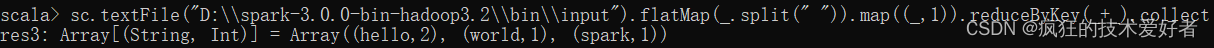
本地 Web UI
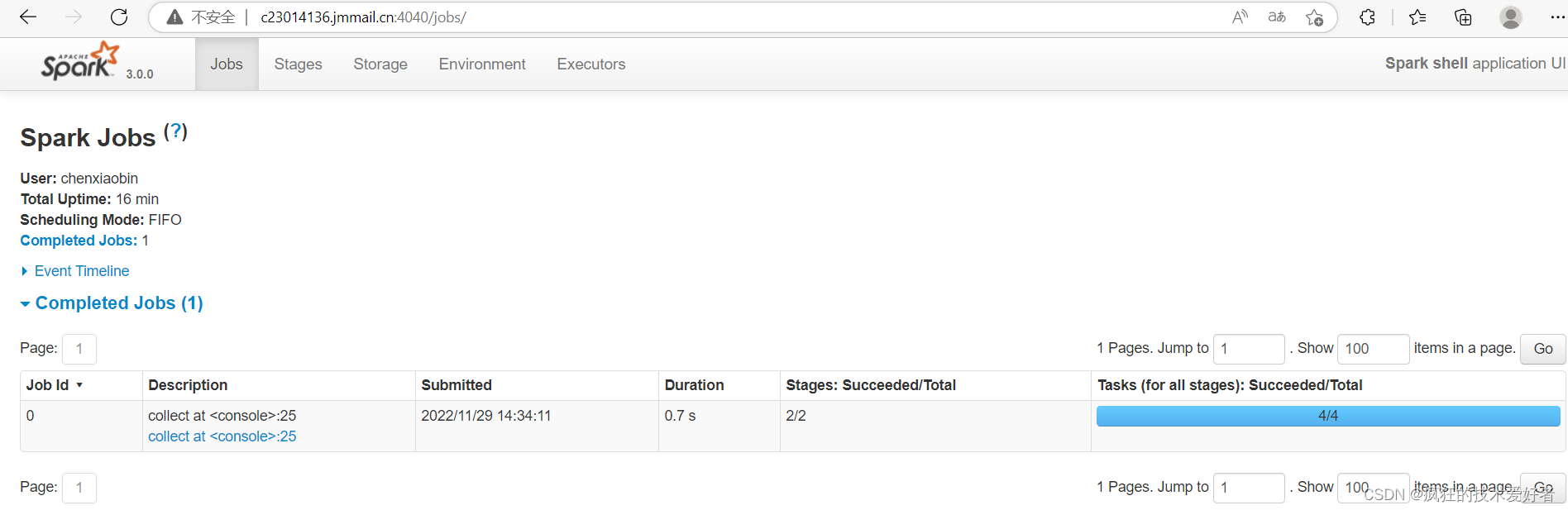
命令行提交应用,在程序bin输入cmd

输入
D:\spark-3.0.0-bin-hadoop3.2\bin>spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10