pytorch复习笔记--loss.backward()、optimizer.step()和optimizer.zero_grad()的用法
创始人
2024-03-04 06:39:35
0次
目录
1--loss.backward()的用法
2--optimizer.step()的用法
3--optimizer.zero_grad()的用法
4--举例说明
5--参考
1--loss.backward()的用法
作用:将损失loss向输入测进行反向传播;这一步会计算所有变量x的梯度值 ,并将其累积为
进行备用,即
,公式中的
指的是上一个epoch累积的梯度。
2--optimizer.step()的用法
作用:利用优化器对参数x进行更新,以随机梯度下降SGD为例,更新的公式为:,lr 表示学习率 learning rate,减号表示沿着梯度的反方向进行更新;
3--optimizer.zero_grad()的用法
作用:清除优化器关于所有参数x的累计梯度值 ,一般在loss.backward()前使用,即清除
。
4--举例说明
① 展示 loss.backward() 和 optimizer.step() 的用法:
import torch# 初始化参数值x
x = torch.tensor([1., 2.], requires_grad=True)# 模拟网络运算,计算输出值y
y = 100*x# 定义损失
loss = y.sum() print("x:", x)
print("y:", y)
print("loss:", loss)print("反向传播前, 参数的梯度为: ", x.grad)
# 进行反向传播
loss.backward() # 计算梯度grad, 更新 x*grad
print("反向传播后, 参数的梯度为: ", x.grad)# 定义优化器
optim = torch.optim.SGD([x], lr = 0.001) # SGD, lr = 0.001print("更新参数前, x为: ", x)
optim.step() # 更新x
print("更新参数后, x为: ", x)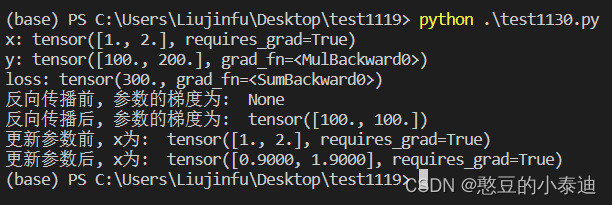
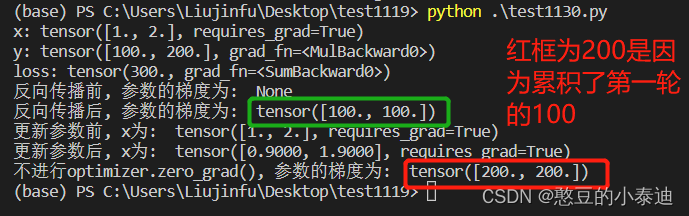
② 展示不使用 optimizer.zero_grad() 的梯度:
import torch# 初始化参数值x
x = torch.tensor([1., 2.], requires_grad=True)# 模拟网络运算,计算输出值y
y = 100*x# 定义损失
loss = y.sum() print("x:", x)
print("y:", y)
print("loss:", loss)print("反向传播前, 参数的梯度为: ", x.grad)
# 进行反向传播
loss.backward() # 计算梯度grad, 更新 x*grad
print("反向传播后, 参数的梯度为: ", x.grad)# 定义优化器
optim = torch.optim.SGD([x], lr = 0.001) # SGD, lr = 0.001print("更新参数前, x为: ", x)
optim.step() # 更新x
print("更新参数后, x为: ", x)# 再进行一次网络运算
y = 100*x# 定义损失
loss = y.sum()# 不进行optimizer.zero_grad()
loss.backward() # 计算梯度grad, 更新 x*grad
print("不进行optimizer.zero_grad(), 参数的梯度为: ", x.grad)
③ 展示使用 optimizer.zero_grad() 的梯度:
import torch# 初始化参数值x
x = torch.tensor([1., 2.], requires_grad=True)# 模拟网络运算,计算输出值y
y = 100*x# 定义损失
loss = y.sum() print("x:", x)
print("y:", y)
print("loss:", loss)print("反向传播前, 参数的梯度为: ", x.grad)
# 进行反向传播
loss.backward() # 计算梯度grad, 更新 x*grad
print("反向传播后, 参数的梯度为: ", x.grad)# 定义优化器
optim = torch.optim.SGD([x], lr = 0.001) # SGD, lr = 0.001print("更新参数前, x为: ", x)
optim.step() # 更新x
print("更新参数后, x为: ", x)# 再进行一次网络运算
y = 100*x# 定义损失
loss = y.sum()# 进行optimizer.zero_grad()
optim.zero_grad()
loss.backward() # 计算梯度grad, 更新 x*grad
print("进行optimizer.zero_grad(), 参数的梯度为: ", x.grad)
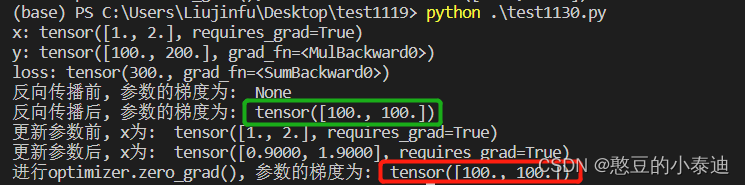
通过②和③的对比,能看出 optimizer.zero_grad() 的作用是清除之前累积的梯度值。
5--参考
参考1
相关内容
热门资讯
美国2年期国债收益率上涨15个...
原标题:美国2年期国债收益率上涨15个基点 美国2年期国债收益率上涨15个基...
汽车油箱结构是什么(汽车油箱结...
本篇文章极速百科给大家谈谈汽车油箱结构是什么,以及汽车油箱结构原理图解对应的知识点,希望对各位有所帮...
嵌入式 ADC使用手册完整版 ...
嵌入式 ADC使用手册完整版 (188977万字)💜&#...
重大消息战皇大厅开挂是真的吗...
您好:战皇大厅这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游戏...
盘点十款牵手跑胡子为什么一直...
您好:牵手跑胡子这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游...
senator香烟多少一盒(s...
今天给各位分享senator香烟多少一盒的知识,其中也会对sevebstars香烟进行解释,如果能碰...
终于懂了新荣耀斗牛真的有挂吗...
您好:新荣耀斗牛这款游戏可以开挂,确实是有挂的,需要了解加客服微信8435338】很多玩家在这款游戏...
盘点十款明星麻将到底有没有挂...
您好:明星麻将这款游戏可以开挂,确实是有挂的,需要了解加客服微信【5848499】很多玩家在这款游戏...
总结文章“新道游棋牌有透视挂吗...
您好:新道游棋牌这款游戏可以开挂,确实是有挂的,需要了解加客服微信【7682267】很多玩家在这款游...
终于懂了手机麻将到底有没有挂...
您好:手机麻将这款游戏可以开挂,确实是有挂的,需要了解加客服微信【8435338】很多玩家在这款游戏...