Linux-Hadoop部署
部署Hadoop
- 一、Hadoop部署模式
- 1、独立模式
- 2、伪分布式模式
- 3、完全分布式模式
- 二、Hadoop集群规划
- 1、集群拓扑
- 2、角色分配
- 三、JDK安装与配置
- 1、下载JDK压缩包
- 2、上传到master虚拟机
- 3、在master虚拟机上安装配置JDK
- 4、将JDK分发到slave1和slave2虚拟机
- 5、将环境配置文件分发到slave1和slave2虚拟机
- 四、Hadoop安装
- 1、下载Hadoop压缩包
- 2、上传Hadoop压缩包到虚拟机
- 3、将Hadoop压缩包解压到指定目录
- 4、配置Hadoop环境变量
- 5、验证Hadoop环境
一、Hadoop部署模式
1、独立模式
在独立模式下,所有程序都在单个JVM上执行,调试Hadoop集群的MapReduce程序也非常方便。一般情况下,该模式常用于学习或开发阶段进行调试程序。
2、伪分布式模式
在伪分布式模式下, Hadoop程序的守护进程都运行在一台节点上,该模式主要用于调试Hadoop分布式程序的代码,以及程序执行是否正确。伪分布式模式是完全分布式模式的一个特例。
3、完全分布式模式
在完全分布式模式下,Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色,在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
二、Hadoop集群规划
1、集群拓扑
- 一个主节点,两个从节点
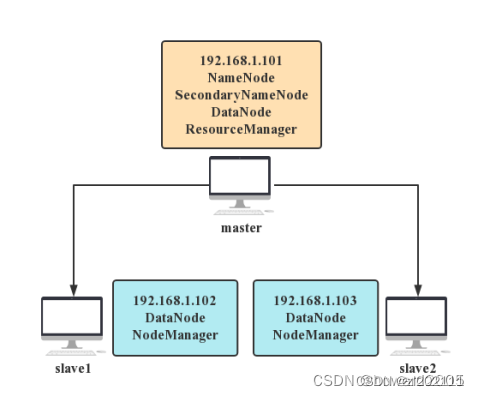
2、角色分配
- 完全分布式Hadoop集群搭建需要在集群的每个节点都安装Hadoop,集群角色分配如下表所示。
| 节点 | 角色 |
|---|---|
| master | NameNode, DataNode |
| slave1 | DataNode |
| slave2 | DataNode |
三、JDK安装与配置
由于Hadoop是由Java语言开发的,Hadoop集群的使用依赖于Java环境,因此安装Hadoop集群之前,需要先安装并配置好JDK。
1、下载JDK压缩包
- 下载链接:Oracle (需要登录Oracle官网才能下载)
- 百度网盘下载:👉jdk221 、👉jdk231
2、上传到master虚拟机
- 将JDK压缩包上传到master虚拟机/opt目录
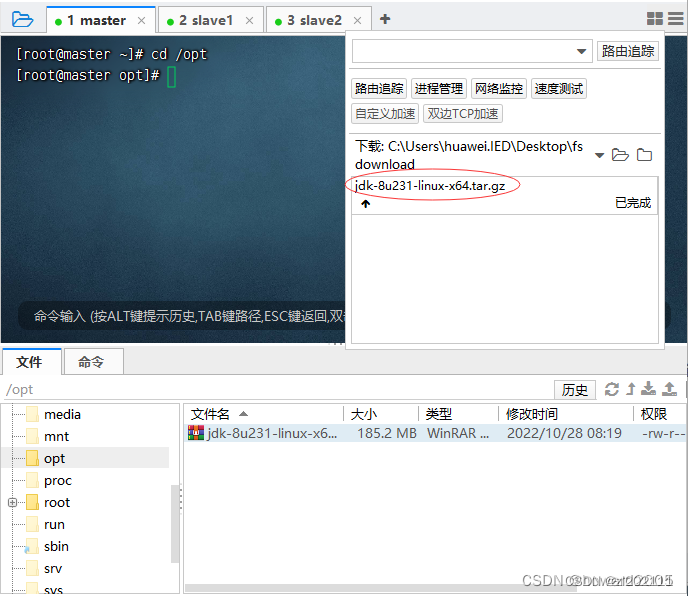
查看上传的JDK压缩包
3、在master虚拟机上安装配置JDK
-
执行命令:
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local,将JDK压缩包解压到指定目录

-
执行命令:
ll /usr/local/jdk1.8.0_231,查看解压之后的jdk1.8.0_231目录
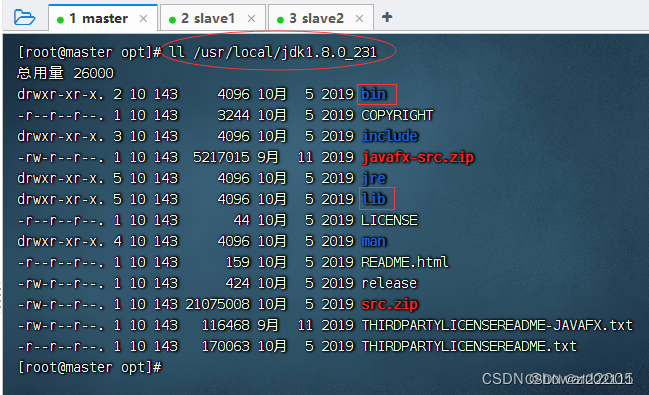
- 执行命令:
vim /etc/profile或vi /etc/profile,配置环境变量
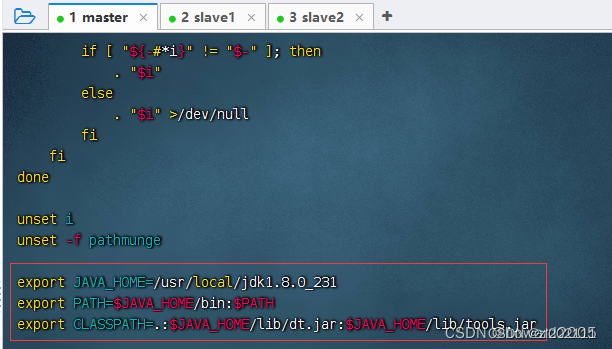
export JAVA_HOME=/usr/local/jdk1.8.0_231
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
-
存盘退出,执行命令:
source /etc/profile,让配置生效
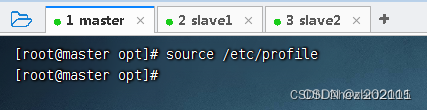
-
查看JDK版本
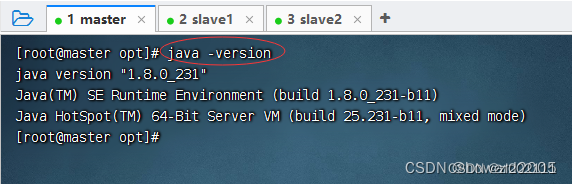
-
编写一个Java程序 - HelloWorld.java
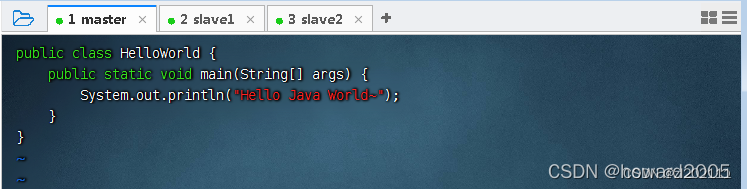
-
存盘退出后,执行命令:
javac HelloWorld.java,编译成字节码文件
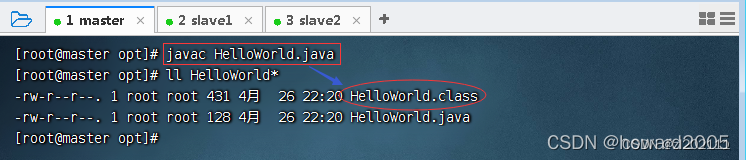
-
执行命令:
java HelloWorld

4、将JDK分发到slave1和slave2虚拟机
执行命令:scp -r $JAVA_HOME root@slave1:$JAVA_HOME (-r:recursive - 递归)
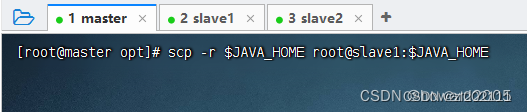
-
在slave1虚拟机上查看JDK是否拷贝成功
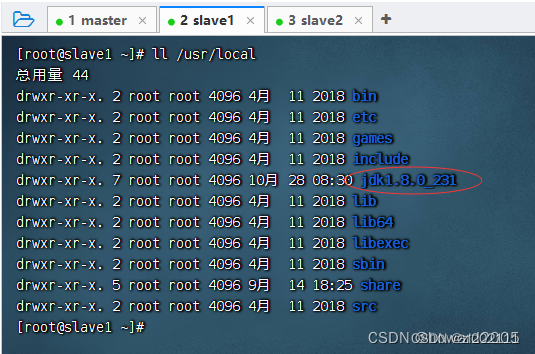
-
执行命令:
scp -r $JAVA_HOME root@slave2:$JAVA_HOME(-r recursive - 递归)
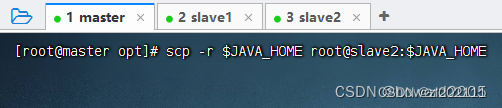
- 在slave2虚拟机上查看JDK是否拷贝成功
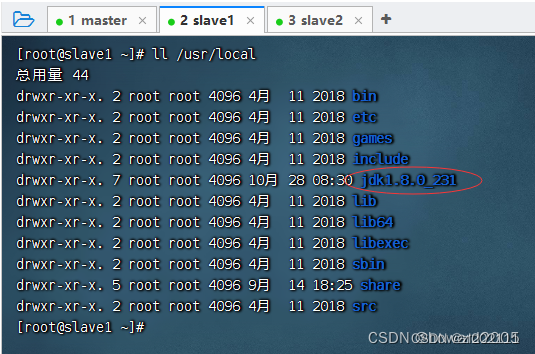
5、将环境配置文件分发到slave1和slave2虚拟机
-
执行命令:
scp /etc/profile root@slave1:/etc

-
执行命令:
scp /etc/profile root@slave2:/etc
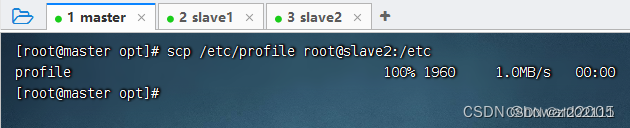
-
在slave1与slave2虚拟机上执行命令:
source /etc/profile,让环境配置生效
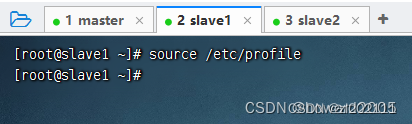
-
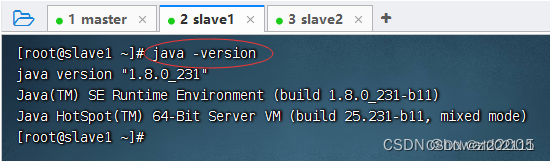
在slave1虚拟机上查看JDK版本
-
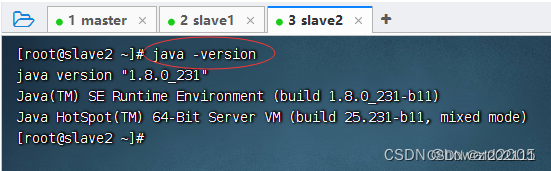
在slave2虚拟机上查看JDK版本
四、Hadoop安装
1、下载Hadoop压缩包
- 下载链接:Hadoop下载
- 百度网盘:hadoop3.3.4
2、上传Hadoop压缩包到虚拟机
-
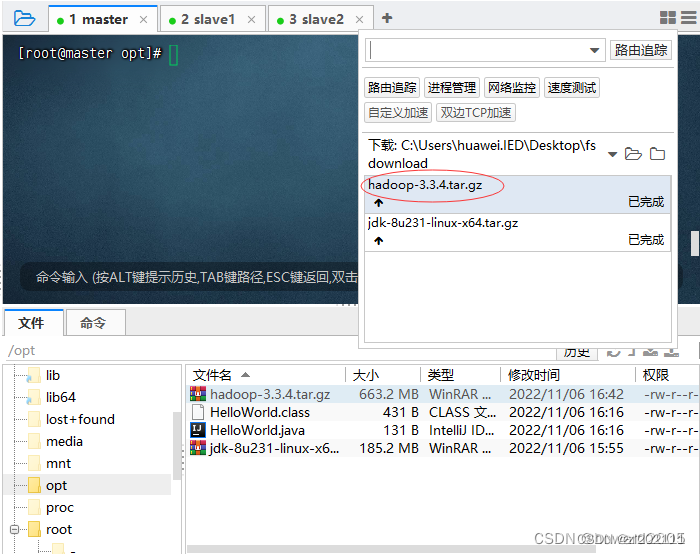
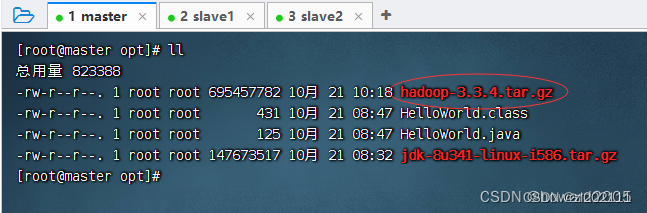
将Hadoop压缩包上传到master虚拟机/opt目录
-
查看上传的Hadoop压缩包
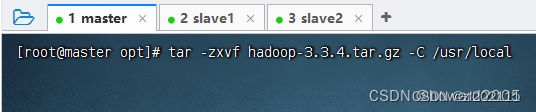
3、将Hadoop压缩包解压到指定目录
-
执行命令:
tar -xzvf hadoop-3.3.4.tar.gz -C /usr/local
-
查看解压之后的hadoop目录
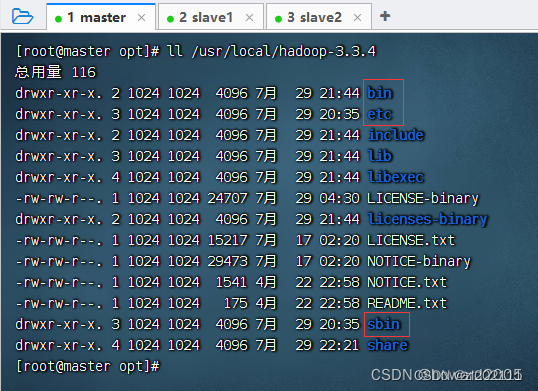
| 目录 | 作用 |
|---|---|
| bin目录 | 命令脚本 |
| etc/hadoop目录 | 存放hadoop的配置文件 |
| lib目录 | hadoop运行的依赖jar包 |
| sbin目录 | 存放启动和关闭hadoop等命令 |
| libexec目录 | 存放的也是hadoop命令,但一般不常用 |
-
在配置Hadoop时,常用的就是
bin、etc与sbin三个目录 -
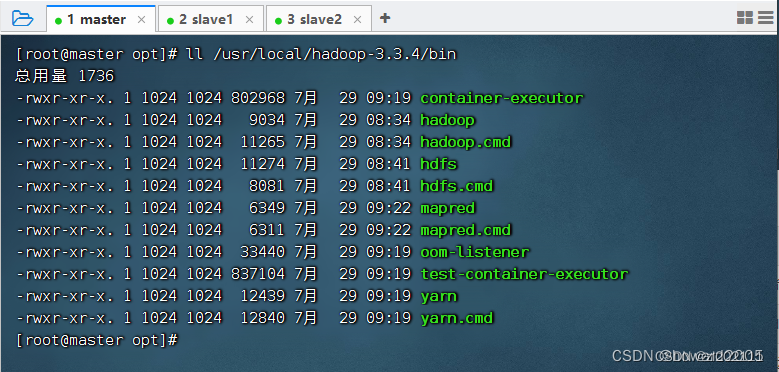
查看
bin目录
-
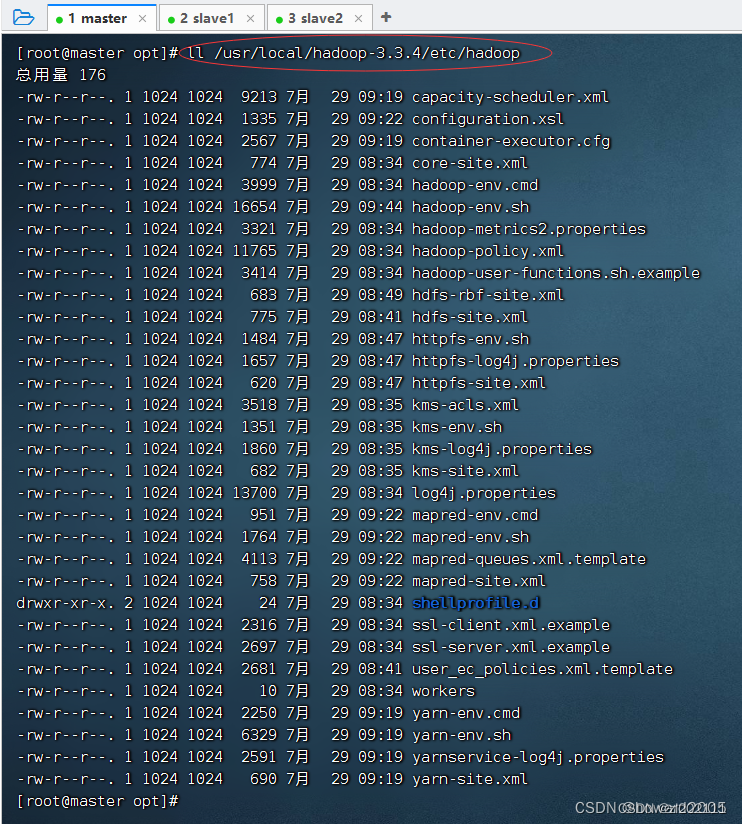
查看
etc/hadoop目录,主要是hadoop配置文件
-
查看sbin目录

4、配置Hadoop环境变量
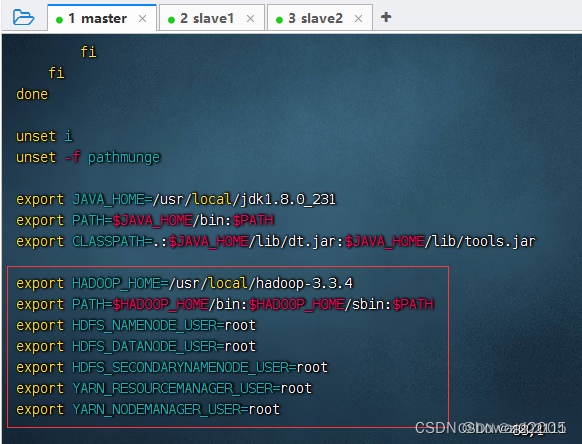
-
执行命令:
vim /etc/profile
-
说明:hadoop 2.x用不着配置用户,只需要前两行即可
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 存盘退出,执行命令
source /etc/profile,让配置生效
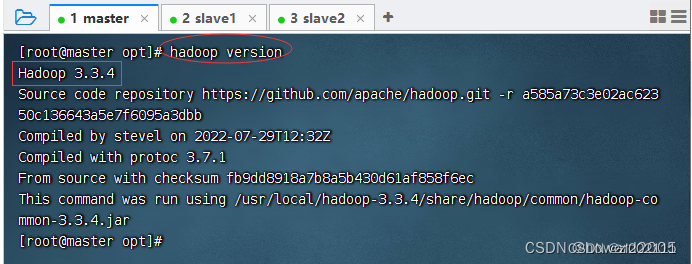
5、验证Hadoop环境
- 执行命令:
hadoop version,检查Hadoop安装是否成功